Den definitiva guiden till Yii 1.1
0 follower
Relationell Active Record
Vi har redan sett hur man kan använda Active Record (AR) till att selektera data från en enstaka databastabell. I det här avsnittet, beskrivs hur man använder AR till att sammanfoga (join) ett antal relaterade databastabeller och lämna den resulterande datamängden i retur.
När relationell AR används, rekommenderas att sambandsrestriktioner (constraints) avseende primärnyckel och referensattribut deklareras för de tabeller som kommer att sammanfogas (join). Restriktionerna hjälper till att upprätthålla korrekthet och integritet för relationellt data.
För enkelhets skull kommer databasschemat som visas i följande entity- relationshipdiagram (ER-diagram) att användas för att illustrera exempel i detta avsnitt.
ER-diagram
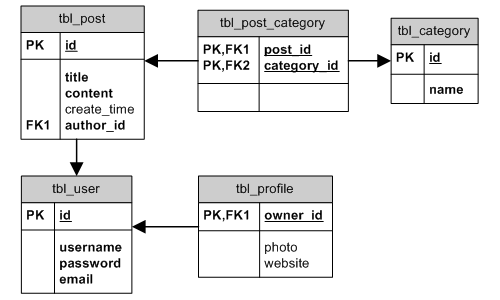
Info: Stödet för referensattributrestriktioner varierar mellan olika databashanterare. SQLite < 3.6.19 stöder inte referensattributrestriktioner, men det går ändå att deklarera restriktionerna när tabeller skapas. MySQL:s MyISAM-motor saknar stöd för referensattributrestriktioner.
1. Deklarera tabellsamband ¶
Innan AR kan användas till att genomföra relationella frågor, måste AR få veta hur en AR-klass relaterar till en annan.
Samband mellan två AR-klasser är direkt förknippat med sambandet mellan
databastabellerna som AR-klasserna representerar. Från databasens synvinkel kan
sambandet mellan två tabeller A and B ha tre typer: en-till-många (t.ex. tbl_user
och tbl_post), en-till-en (t.ex. tbl_user och tbl_profile) samt många-till-många
(t.ex. tbl_category och tbl_post). Inom AR finns det fyra sorters samband:
BELONGS_TO: om sambandet mellan tabellerna A och B är en-till-många, så är B tillhörig A (t.ex.PosttillhörUser);HAS_MANY: om sambandet mellan tabellerna A och B är en-till-många, så har A många B (t.ex.Userhar mångaPost);HAS_ONE: detta är ett specialfall avHAS_MANYdär A har som mest en B (t.ex.Userhar som mest enProfile);MANY_MANY: detta motsvarar många-till-mångasambandet i databasen. En assisterande tabell erfordras för att bryta upp ett många-till-mångasamband i ett-till-mångasamband, eftersom de flesta databashanterare saknar direkt stöd för många-till-mångasamband. I vårt exempelschema, tjänartbl_post_categorydetta syfte. Med AR terminology kanMANY_MANYförklaras som kombinationen avBELONGS_TOochHAS_MANY. Till exempel,Posttilhör mångaCategoryochCategoryhar mångaPost.
Tabellsamband deklareras i AR genom att metoden relations() i CActiveRecord åsidosätts. Denna metod returnerar en array med sambandskonfigurationer. Varje element i denna array representerar ett enstaka samband, på följande format:
'VarName'=>array('RelationType', 'ClassName', 'ForeignKey', ...additional options)där VarName är sambandets namn; RelationType specificerar sambandets typ,
som kan vara en av de fyra konstanterna: self::BELONGS_TO, self::HAS_ONE,
self::HAS_MANY samt self::MANY_MANY; ClassName är namnet på den AR-klass
som har samband med denna AR-klass; ForeignKey specificerar det eller de
referensattribut som är involverade i sambandet. Ytterligare alternativ kan
specificeras i slutet av varje sambandsdeklaration (beskrivs längre fram).
Följande kod visar hur sambandet mellan klasserna User och Post deklareras.
class Post extends CActiveRecord
{
......
public function relations()
{
return array(
'author'=>array(self::BELONGS_TO, 'User', 'author_id'),
'categories'=>array(self::MANY_MANY, 'Category',
'tbl_post_category(post_id, category_id)'),
);
}
}
class User extends CActiveRecord
{
......
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id'),
'profile'=>array(self::HAS_ONE, 'Profile', 'owner_id'),
);
}
}Info: Ett referensattribut kan vara sammansatt och bestå av två eller flera kolumner. I det fallet skall namnen på kolumner som ingår i referensattributet skrivas efter varandra, separerade av kommatecken alternativt som en vektor så som array('key1','key2'). I fallet att anpassade PK->FK associationer behöver specificeras kan formatet array('fk'=>'pk') användas. För sammansatta nycklar blir det array('fk_c1'=>'pk_c1','fk_c2'=>'pk_c2'). För samband av typen
MANY_MANYmåste namnet på den assisterande tabellen också specificeras i referensattributet. Till exempel, sambandetcategoriesiPostär specificerat med referensattributettbl_post_category(post_id, category_id). Deklarationen av samband i en AR-klass lägger underförstått till en property i klassen för varje samband. När en relationell fråga har utförts kommer den motsvarande propertyn att innehålla den relaterade AR-instansen(-erna). Till exempel, om$authorrepresenterar en AR-instansUser, kan$author->postsanvändas för tillgång till dess relateradePost-instans.
2. Utföra relationell fråga ¶
Det enklaste sättet att utföra en relationell fråga är genom att läsa en relationell property i en AR-instans. Om denna property inte har lästs tidigare kommer en relationell fråga att initieras, som slår samman de två relaterade tabellerna och filtrerar med primärnyckeln i aktuell AR-instans. Frågeresultatet kommer att sparas i propertyn som en eller flera instanser av den relaterade AR- klassen. Detta förfarande är känt som lazy loading, dvs den relationella frågan utförs först när relaterade objekt refereras till första gången. Exemplet nedan visar hur man använder detta tillvägagångssätt:
// retrieve the post whose ID is 10
$post=Post::model()->findByPk(10);
// retrieve the post's author: a relational query will be performed here
$author=$post->author;Info: Om det saknas en relaterad instans i ett samband kan den motsvarande propertyn anta värdet null eller en tom array. För sambanden
BELONGS_TOochHAS_ONE, är resultatet null; förHAS_MANYochMANY_MANY, är det en tom array. Märk att sambandstypernaHAS_MANYochMANY_MANYreturnerar arrayer av objekt, därför behöver man iterera över resultatet för att komma åt propertyn. Om man inte gör detta erhålls felet "Trying to get property of non-object".
Tillvägagångssättet med lazy loading är mycket bekvämt att använda, men har
lägre prestanda i vissa scenarier. Till exempel, om vi vill få tillgång till
information om författare för N postningar, kommer tillvägagångssättet lazy
att omfatta körning av N join-frågor. Under dessa omständigheter bör det
alternativa tillvägagångssättet, kallat eager loading, användas.
Tillvägagångssättet eager loading hämtar in relaterade AR-instanser tillsammans med huvudinstansen (-instanserna). Detta åstadkommes genom användning av metoden with() tillsammans med en av find- eller findAll-metoderna i AR. Till exempel,
$posts=Post::model()->with('author')->findAll();Ovanstående kod returnerar en array bestående av Post-intanser. Till skillnad
från tillvägagångssättet lazy, är propertyn author i varje instans av Post
redan laddad med den relaterade User-instansen redan innan vi refererar till
propertyn. I stället för att exekvera en join-fråga för varje postning, hämtar
tillvägagångssättet eager loading in samtliga postningar tillsammans med deras
respektive författare, alltsammans i en enda join-fråga!
Man kan specificera flera sambandsnamn till metoden with() och tillvägagångssättet eager loading kommer att hämta in dem alla i ett moment. Till exempel, följande kod hämtar in postningar tillsammans med deras repektive författare och kategorier:
$posts=Post::model()->with('author','categories')->findAll();Det går att använda nästlad eager loading. I stället för en lista med sambandsnamn, lämnar vi med en hierarkisk representation av sambandsnamnen till metoden with(), som i följande exempel,
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->findAll();Ovanstående exempel hämtar in alla postningar tillsammans med deras respektive författare och kategorier. Det hämtar även in varje författares profil samt postningar.
Eager loading kan även exekveras genom att man specificerar propertyn CDbCriteria::with, som i följande exempel:
$criteria=new CDbCriteria;
$criteria->with=array(
'author.profile',
'author.posts',
'categories',
);
$posts=Post::model()->findAll($criteria);eller
$posts=Post::model()->findAll(array(
'with'=>array(
'author.profile',
'author.posts',
'categories',
)
));3. Genomföra relationell fråga utan att hämta relaterade modeller ¶
Ibland vill vi utföra frågor som använder samband, utan att hämta in relaterade modeller.
Antag att vi har User-poster som skapat många Post-poster. Post kan ha status publicerad
men kan även ha utkaststatus. Detta bestäms av fältet published i modellen Post.
Ny vill vi hämta alla användare som har publicerade postningar utan att inkludera själva
postningarna. Detta kan upppnås på följande sätt:
$users=User::model()->with(array(
'posts'=>array(
// vi vill inte selektera fält från postningar
'select'=>false,
// men vi vill bara ha användare med publicerade postningar
'joinType'=>'INNER JOIN',
'condition'=>'posts.published=1',
),
))->findAll();4. Alternativ för relationella frågor ¶
Som nämnts kan ytterligare alternativ anges i sambandsdeklarationer. Dessa alternativ, specificerade i form av namn-värdepar, används för att anpassa den relationella frågan. De sammanfattas nedan.
select: en lista med med kolumner som skall selekteras till den relaterade AR-klassen. Den har standardvärdet '*', vilket innebär alla kolumner. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga.condition: motsvararWHERE-ledet. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga.params: parametrarna som skall kopplas ihop med den genererade SQL-satsen. Dessa skall ges som en array bestående av namn-värdepar.on: motsvararON-ledet. Villkoret som specificeras här kommer att läggas till sammanslagningsvillkoret med hjälp avAND-operatorn. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga. Detta alternativ är inte relevant vidMANY_MANY-samband.order: motsvararORDER BY-ledet. Det är som standard tomt. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga.with: en lista med underordnade relaterade objekt som skall laddas tillsammans med detta objekt. Var uppmärksam på att om detta alternativ används olämpligt, kan det leda till en ändlös slinga av relationer.joinType: typ av sammanslagning för detta samband. Den är som standardLEFT OUTER JOIN.alias: aliasnamn för tabellen som förknippas med detta samband. Standardvärde är null, vilket innebär att tabellalias genereras automatiskt. Detta skiljer sig frånaliasTokenpå så sätt att den senare bara är en platshållare och ersätts med faktiskt tabellalias.together: huruvida tabellen associerad med detta samband skall tvingas till en ovillkorlig sammanfogning (join) med den primära tabellen och andra tabeller. Detta alternativ är endast relevant för samband av typernaHAS_MANYochMANY_MANY. Om alternativet sätts till false, kommer tabellen som är associerad medHAS_MANY- ellerMANY_MANY-sambandet att sammanfogas med den primära tabellen i en separat SQL-fråga, något som kan öka total frågeprestanda eftersom mindre mängd redundant data returneras. Om detta alternativ sätts till true, kommer den associerade tabellen alltid att sammanfogas med den primära tabellen i en och samma SQL-fråga, även om den primära tabellen sidindelas. Om detta alternativ inte sätts, kommer den associerade tabellen att sammanfogas med den primära tabellen i en och samma SQL-fråga, endast när den primära tabellen inte sidindelas. För fler detaljer se avsnittet "Relational Query Performance".join: ett tillkommandeJOIN-led. Det är som standard tomt. Detta alternativ har varit tillgängligt sedan version 1.1.3.group: motsvararGROUP BY-ledet. Det är som standard tomt. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga.having: motsvararHAVING-ledet. Det är som standard tomt. Kolumnnamn som refereras till i detta alternativ måste göras otvetydiga.index: namnet på kolumnen vars värden skall användas som nycklar i den array som lagrar relaterade objekt. Om detta alternativ inte sätts kommer en relaterad objektarray att använda ett nollbaserat heltalsindex. Detta alternativ kan endast sättas för sambandstypernaHAS_MANYochMANY_MANY.scopes: omfång som skall tillämpas. Ett enstaka omfång kan anges som'scopes'=>'scopeName', för flerfaldiga omfång används formatet'scopes'=>array('scopeName1','scopeName2'). Detta alternativ blev tillgängligt i version 1.1.9.
Dessutom är följande alternativ tillgängliga för vissa samband när lazy loading används:
limit: begränsar antalet rader som kan selekteras. Detta alternativ är INTE tillämpligt påBELONGS_TO-samband.offset: offset till rader som skall selekteras. Detta alternativ är INTE tillämpligt påBELONGS_TO-samband.through: namnet på en modells samband, vilket skall användas som brygga vid hämtning av relaterad data. Kan tillämpas enbart påHAS_ONE- ochHAS_MANY-samband. Detta alternativ har varit tillgängligt sedan version 1.1.7.
Nedan har deklarationen av sambandet posts i User varierats genom
inkludering av några av ovanstående alternativ:
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'order'=>'posts.create_time DESC',
'with'=>'categories'),
'profile'=>array(self::HAS_ONE, 'Profile', 'owner_id'),
);
}
}Om vi nu refererar till $author->posts, kommer vi att erhålla författarens
postningar sorterade i fallande ordning efter tid de skapats. Varje instans av
postning har också fått sina kategorier laddade.
Info: När ett kolumnnamn uppträder i två eller fler tabeller som slås samman (join), behöver det göras otvetydigt. Detta åstadkommes genom att föregå kolumnnamnet med dess tabellnamn. Till exempel,
idblirTeam.id. I AR:s relationella frågor däremot, saknas denna frihet eftersom SQL-satserna genereras automatiskt av AR, vilket systematiskt ger varje tabell ett alias. Av denna anledning används, för att undvika konflikter mellan kolumnnamn, en platshållare för att indikera förekomsten av en kolumn som behöver göras otvetydig. AR ersätter platshållaren med ett passande tabellalias och gör kolumnen otvetydig.
5. Göra kolumnnamn otvetydiga ¶
När ett kolumnnamn förekommer i två eller fler tabeller som sammanfogas, behöver det göras otvetydigt. Detta gör man genom att skjuta in tabellens aliasnamn före kolumnnamnet.
I en relationell AR-fråga är aliasnamnet för den primära tabellen alltid t,
medan aliasnamnet för en relaterad tabell som standard är samma som det motsvarande
sambandets namn. Till exempel så har Post och Comment i följande exempel,
aliasnamnen t respektive comments:
$posts=Post::model()->with('comments')->findAll();Antag nu att både Post och Comment har en kolumn create_time som indikerar
tiden en postning respektive kommentar skapats och att vi vill hämta postningar
tillsammans med tillhörande kommentarer samt sortera dessa efter först postningarnas
därefter kommentarernas skapandetid. Vi behöver då göra kolumnen create_time otvetydig
på följande sätt:
$posts=Post::model()->with('comments')->findAll(array(
'order'=>'t.create_time, comments.create_time'
));6. Alternativ för dynamisk relationell fråga ¶
Det går att använda alternativ för dynamisk relationell fråga både med metoden with()
och med with-alternativet. De dynamiska alternativen skriver över existerande
alternativ som specificerats i metoden relations().
Till exempel, för att, med ovanstående User-modell, använda tillvägagångssättet
eager loading till att hämta in postningar tillhörande en författare i stigande
ordningsföljd (order-alternativet i sambandet specificerar fallande
ordningsföljd), kan man göra följande:
User::model()->with(array(
'posts'=>array('order'=>'posts.create_time ASC'),
'profile',
))->findAll();Dynamiska frågealternativ kan även användas med relationella frågor som använder tillvägagångssättet lazy loading. För att göra så, anropa en metod vars namn är lika sambandsnamnet och lämna med de dynamiska frågealternativen som metodparameter. Till exempel returnerar följande kod de av en användares postningar vars status` är lika med 1:
$user=User::model()->findByPk(1);
$posts=$user->posts(array('condition'=>'status=1'));7. Prestanda för relationell fråga ¶
Som beskrivits ovan används tillvägagångssättet eager loading huvudsakligen i ett scenario där vi behöver accessa många relaterade objekt. Det genererar en stor komplex SQL-sats genom att utföra join med alla tabeller som behövs. En stor SQL-sats är att föredra i många fall eftersom den förenklar filtrering baserad på en kolumn i en relaterad tabell. Dock kan den vara mindre effektiv i vissa fall.
Tänk ett exempel där vi behöver hitta de senaste postningarna tillsammans med tillhörande kommentarer. Med antagandet att varje postning har 10 kommentarer och en enda stor SQL-sats, kommer en stor mängd redundant data om postningar att returneras eftersom varje postning kommer att repeteras för varje tillhörande kommentar. Tänk ett annat tillvägagångssätt: först en fråga om senaste postningarna, därefter en fråga om tillhörande kommentarer. Vid detta nya tillvägagångssätt, behöver två SQL-satser exekveras. Vinsten är att det inte kommer med reduntant data i frågeresultatet.
Så vilket tillvägagångssätt är mer effektivt? Det finns inget absolut svar. Att exekvera en enstaka stor SQL-sats kan vara mer effektivt eftersom det leder till mindre overhead i DBMS:en för parsning och exekvering av SQL-satser. Å andra sidan, vid användning av en enstaka SQL-sats, kommer det att gå åt mer tid till att läsa och bearbeta den större mängden redundant data.
Av detta skäl, tillhandahåller Yii frågealternativet together så att vi kan välja mellan de två tillvägagångssätten.
Som standard använder sig Yii av eager loading, dvs, att skapa en enda SQL-sats, utom när LIMIT är åsatt
den primära modellen. Genom att sätta alternativet together till true i sambandsdeklarationen kan en enstaka
SQL-sats tvingas fram, även när LIMIT används. Om alternativet together sätts till false sker join mellan
vissa tabeller i separata SQL-satser. Till exempel, för att använda det andra tillvägagångssättet i samband med
en fråga om de senaste postningarna med tillhörande kommentarer, kan vi deklarera sambandet comments i
Post-klassen på följande sätt,
public function relations()
{
return array(
'comments' => array(self::HAS_MANY, 'Comment', 'post_id', 'together'=>false),
);
}Vi kan även sätta detta alternativ dynamiskt när vi genomför eager loading:
$posts = Post::model()->with(array('comments'=>array('together'=>false)))->findAll();8. Statistikfråga ¶
Utöver relationella frågor som beskrivits ovan, stöder Yii också så kallade statistikfrågor
(eller aggregationsfrågor). Detta refererar till inhämtning av aggregeringsinformation om
relaterade objekt, såsom antalet kommentarer till varje postning, den genomsnittliga
poängsättningen för varje produkt, etc. Statistikfrågor kan endast utföras mot objekt som har
sambandstyperna HAS_MANY (t.ex. en postning har många kommentarer) eller MANY_MANY
(t.ex. en postning tillhör många kategorier och en kategori har många postningar).
Att genomföra en statistikfråga är mycket snarlikt till att utföra en relationell fråga, som tidigare besrivits. Först deklareras en statistikfråga i metoden relations() i CActiveRecord precis som vid en relationell fråga.
class Post extends CActiveRecord
{
public function relations()
{
return array(
'commentCount'=>array(self::STAT, 'Comment', 'post_id'),
'categoryCount'=>array(self::STAT, 'Category', 'post_category(post_id, category_id)'),
);
}
}Ovan deklareras två statistikfrågor: commentCount beräknar antalet kommentarer som tillhör
en postning och categoryCount beräknar antalet kategorier en postning tillhör.
Märk att sambandstypen mellan between Post och Comment är HAS_MANY, medan sambandstypen
mellan Post och Category är MANY_MANY (med hjälp av mellantabellen post_category).
Som tydligt framgår är deklarationen mycket snarlik de sambandsdeklarationer som beskrivits
i tidigare delavsnitt. Den enda skillnaden är att sambandstypen STAT används här.
Med ovanstående deklaration kan vi hämta antalet kommentarer till en postning med hjälp av
uttrycket $post->commentCount. När vi använder denna property första gången, kommer en
SQL-sats att exekveras implicit för att hämta in det önskade resultatet.
Som bekant är detta den så kallade lazy loading-metoden. Vi kan även använda
eager loading-metoden om vi behöver avgöra antalet kommentarer för ett flertal postningar:
$posts=Post::model()->with('commentCount', 'categoryCount')->findAll();Ovanstående programsats exekverar tre SQL-satser för att leverera alla postningar tillsammans
med deras respektive kommentarantal och antal kategorier. Om lazy loading-metoden används
blir resultatet att 2*N+1 SQL-frågor exekveras givet N postningar.
Som standard kalkylerar en statistikfråga COUNT-uttrycket (och därmed kommentarantalet och
antalet kategorier i ovanstående exempel). Detta kan vi anpassa genom att ange ytterligare
alternativ när vi deklarerar relations().
De tillgängliga alternativen summeras nedan.
select: statistikfrågan. Som standardCOUNT(*), innebärande antalet underordnade objekt.defaultValue: värde som skall tilldelas de poster som inte erhåller ett resultat från statistikfrågan. Till exempel, om en postning inte har några kommentarer, kommer desscommentCountatt åsättas detta värde. Standardvärde för detta alternativ är 0.condition:WHERE-ledet. Som standard tomt.params: parametrarna som skall kopplas till den genererade SQL-satsen. De skall anges som en array av namn-värdepar.order:ORDER BY-ledet. Som standard tomt.group:GROUP BY-ledet. Som standard tomt.having:HAVING-ledet. Som standard tomt.
9. Relationell fråga med namngivna omfång ¶
Relationella frågor kan även utföras i kombination med namngivna omfång. Detta kan ske i två former. I den första formen appliceras namngivna omfång på huvudmodellen. I den andra formen appliceras namngivna omfång på relaterade modeller.
Följande kod visar hur namngivna omfång appliceras på huvudmodellen.
$posts=Post::model()->published()->recently()->with('comments')->findAll();Detta är mycket snarlikt icke-relationella frågor. Den enda skillnaden är
anropet av with() efter kedjan av namngivna omfång. Ovanstående fråga skulle
hämta nyligen publicerade postningar tillsammans med dess kommentarer.
Fäljande kod visar hur namngivna omfång appliceras på relaterade modeller.
$posts=Post::model()->with('comments:recently:approved')->findAll();
// eller sedan 1.1.7
$posts=Post::model()->with(array(
'comments'=>array(
'scopes'=>array('recently','approved')
),
))->findAll();
// eller sedan 1.1.7
$posts=Post::model()->findAll(array(
'with'=>array(
'comments'=>array(
'scopes'=>array('recently','approved')
),
),
));Ovanstående fråga skulle hämta alla postningar tillsammans med deras för publicering
godkända kommentarer. Märk att comments refererar till sambandsnamnet,
medan recently och approved refererar till två namngivna omfång som deklarerats
i modellklassen Comment. Sambandsnamnet och de namngivna omfången skall separeras med kolon.
Namngivna omfång kan även specificeras med alternativet with i sambandsdeklarationen i
CActiveRecord::relations(). I följande exempel kommer - om vi accessar $user->posts -
alla postningarnas godkända (för publicering) kommentarer att hämtas.
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'with'=>'comments:approved'),
);
}
}
// eller sedan 1.1.7
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'with'=>array(
'comments'=>array(
'scopes'=>'approved'
),
),
),
);
}
}Märk: Före 1.1.7 gällde att namngivna omfång som appliceras på relaterade modeller måste specificeras i CActiveRecord::scopes. Detta medför att de inte kan parametriseras.
Sedan version 1.1.7 är det möjligt att lämna med parametrar för relationella namngivna omfång.
Till exempel, ett omfång med namnet rated i modellen Post som accepterar minsta önskade
ratingvärde för en postning, kan användas på följande sätt från modellen User:
$users=User::model()->findAll(array(
'with'=>array(
'posts'=>array(
'scopes'=>array(
'rated'=>5,
),
),
),
));10. Relationell fråga med 'through' ¶
Vid användning av through skall sambandsdefinitionen se ut som följer:
'comments'=>array(self::HAS_MANY,'Comment',array('key1'=>'key2'),'through'=>'posts'),I ovanstående array('key1'=>'key2'):
key1är en nyckel definierad i sambandet som specificeras ithrough(i detta fallposts).key2är en nyckel definierad i modellen detta samband (comments) refererar till (i detta fallComment).
through kan användas med HAS_ONE- och HAS_MANY-samband.
HAS_MANY through
HAS_MANY through ER
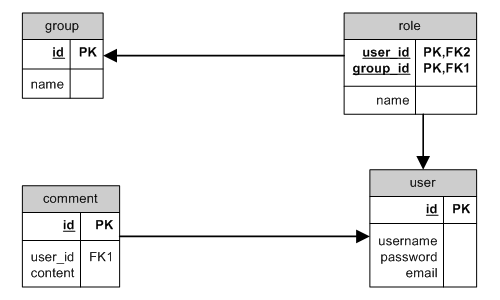
Ett exempel på HAS_MANY med through är att hämta användare tillhörande
en specifik grupp när användare är tilldelade grupp via roller.
Ett mer komplext exempel är att hämta samtliga kommentarer för alla användare
tillhörande en specifik grupp . I detta fall behöver vi använda flera samband
med through, i en enda modell:
class Group extends CActiveRecord
{
...
public function relations()
{
return array(
'roles'=>array(self::HAS_MANY,'Role','group_id'),
'users'=>array(self::HAS_MANY,'User',array('user_id'=>'id'),'through'=>'roles'),
'comments'=>array(self::HAS_MANY,'Comment',array('id'=>'user_id'),'through'=>'users'),
);
}
}Användningsexempel
// hämta alla grupper samt alla tillhörande användare
$groups=Group::model()->with('users')->findAll();
// hämta alla grupper med alla tillhörande användare och roller
$groups=Group::model()->with('roles','users')->findAll();
// hämta alla användare och roller för vilka grupp-ID är 1
$group=Group::model()->findByPk(1);
$users=$group->users;
$roles=$group->roles;
// hämta alla kommentarer för vilka grupp-ID är 1
$group=Group::model()->findByPk(1);
$comments=$group->comments;HAS_ONE through
HAS_ONE through ER
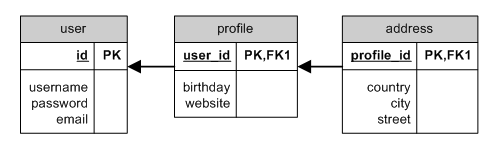
Ett exempel på användning av HAS_ONE med through är att hämta en användares adress
när användaren är kopplad till addressen genom en profil. Alla dessa entiteter
(user, profile, och address) har motsvarande modeller:
class User extends CActiveRecord
{
...
public function relations()
{
return array(
'profile'=>array(self::HAS_ONE,'Profile','user_id'),
'address'=>array(self::HAS_ONE,'Address',array('id'=>'profile_id'),'through'=>'profile'),
);
}
}Användningsexempel
// hämta adressen för en användare vars ID är 1
$user=User::model()->findByPk(1);
$address=$user->address;Egensamband med through
through kan användas för en modell som relaterar till sig själv via en bryggmodell.
I exemplet handlar det om en användare som är mentor för andra användare:
through self ER
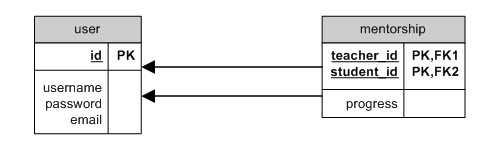
I detta fall definierar vi sambandet så här:
class User extends CActiveRecord
{
...
public function relations()
{
return array(
'mentorships'=>array(self::HAS_MANY,'Mentorship','teacher_id','joinType'=>'INNER JOIN'),
'students'=>array(self::HAS_MANY,'User',array('student_id'=>'id'),'through'=>'mentorships','joinType'=>'INNER JOIN'),
);
}
}Användningsexempel
// hämta alla studenter som undervisas av läraren vars ID är 1
$teacher=User::model()->findByPk(1);
$students=$teacher->students;
Found a typo or you think this page needs improvement?
Edit it on github !
Signup or Login in order to comment.