Das umfassende Handbuch für Yii 1.1
0 follower
Relationale ActiveRecords
Wie man mit ActiveRecord Tabellendaten ausliest, haben wir bereits gezeigt. In diesem Abschnitt soll es darum gehen, wie man mit AR Abfragen über mehrere verknüpfte Tabellen ausführt.
Will man mit relationalen AR arbeiten, sollten in der Datenbank Constraints (sinngem.: Zwangsbedingungen) für Fremdschlüssel definiert sein, um die Konsistenz und Integrität der Daten zu gewährleisten.
Für die Beispiele in diesem Abschnitt verwenden wir dieses einfache Beziehungsmodell:
ER-Diagramm
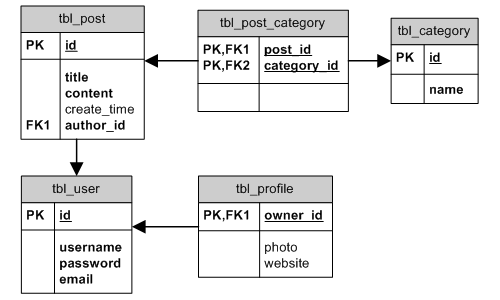
Info: Je nach DBMS werden Fremdschlüssel-Constraints auf unterschiedliche Arten unterstützt. So verwendet z.B. SQLite vor Version 3.6.19 keine Constraints. Man kann sie aber trotzdem beim Erstellen einer Tabelle angeben. MySQLs MyISAM-Engine kann gar keine Constraints.
1. Angeben von Beziehungen ¶
Bevor man relationale Abfragen mit AR durchführen kann, müssen die Beziehungen zwischen den beteiligten AR-Klassen definiert werden.
Diese AR-Beziehungen gleichen denen der entsprechenden Datenbanktabellen.
In der Datenbank können zwei Tabellen A und B auf drei Arten miteinander
verknüpft sein: eins-zu-viele (1:n, z.B. zwischen tbl_user und tbl_post),
eins-zu-eins (1:1, z.B. zwischen tbl_user und tbl_profile) und
viele-zu-viele (n:m, z.B. zwischen tbl_category und
tbl_post). In AR sind vier Typen möglich:
BELONGS_TO(gehört): Wenn die Tabellen A und B 1:n-verknüpft sind, dann gilt: B gehört A (z.B.PostgehörtUser).HAS_MANY(hat viele): Auf der anderen Seite gilt bei der selben 1:n-Verknüpfung zwischen A und B: A hat viele B (z.B.Userhat vielePost).HAS_ONE(hat ein): Dies ist ein Spezialfall vonHAS_MANY, wobei A höchstens ein B hat (z.B.Userhat höchstens einProfile).MANY_MANY(viele viele): Dies entspricht der n:m-Beziehung in der Datenbank. Eine Verbindungstabelle wird benötigt, um die n:m-Beziehung mit zwei 1:n-Beziehungen abzubilden, da die meisten DBMS n:m-Beziehungen nicht direkt unterstützen. In unserem Beispiel isttbl_post_categoryeine solche Tabelle. In AR-Terminologie kann man eineMANY_MANY-Beziehung als Kombination einerBELONGS_TO- und einerHAS_MANY-Beziehung sehen. Beispielsweise gehörtPostzu vielenCategoryundCategoryhat vielePost.
Beziehungen werden in AR definiert, indem man die relations()-Methode von CActiveRecord überschreibt. Sie liefert ein Array zurück, in dem jedes Element für eine einzelne Beziehung steht:
'VarName'=>array('RelationsTyp', 'KlassenName', 'FremdSchlüssel', ...Zusätzliche Optionen)VarName gibt den Namen, RelationsTyp die Art der Beziehung an. Sie wird
mit einer der vier Konstanten self::BELONGS_TO, self::HAS_ONE,
self::HAS_MANY und self::MANY_MANY festgelegt. KlassenName ist der Name
der AR-Klasse, zu der die Beziehung besteht. FremdSchlüssel gibt den/die zu
verwendenden Fremdschlüssel an. Schließlich können für jede Definition noch
weitere Optionen angegeben werden (worauf wir weiter unten noch genauer eingehen).
Hier ein Beispiel, wie die Beziehung zwischen User und Post angegeben
wird:
class Post extends CActiveRecord
{
public function relations()
{
return array(
'author'=>array(self::BELONGS_TO, 'User', 'author_id'),
'categories'=>array(self::MANY_MANY, 'Category',
'tbl_post_category(post_id, category_id)'),
);
}
}
class User extends CActiveRecord
{
......
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id'),
'profile'=>array(self::HAS_ONE, 'Profile', 'owner_id'),
);
}
}Info: Es gibt auch zusammengesetzte Fremdschlüssel, die zwei oder mehr Spalten verwenden. In diesem Fall müssen alle Spaltennamen des Fremdschlüssels hintereinander mit Komma getrennt oder als Array der Form
array('key1','key2')angegeben werden. Falls man eigene Zuordnungen von Primär- nach Fremdschlüssel angeben möchte, kann man dies alsarray('fk'=>'pk')tun. Für zusammengesetzte Schlüssel sieht das Array entsprechend so aus:array('fk_c1'=>'pk_с1','fk_c2'=>'pk_c2'). Außerdem benötigt die MANY_MANY-Beziehung zusätzlich den Namen der Verknüpfungstabelle. Er wird zusammen mit dem Fremdschlüssel wie in diesem Beispiel für diecategories-Beziehung inPostangegeben:tbl_post_category(post_id, category_id).
Für jede dieser Beziehungsdefinitionen wird automatisch eine implizite
Eigenschaft in der AR-Klasse erzeugt, über die man auf die entsprechend
verknüpften AR-Objekte zugreifen kann, nachdem eine relationale Abfrage
durchgeführt wurde. Ist $author z.B. Instanz der AR-Klasse User,
stehen in $author->posts verknüpften Post-Instanzen zur Verfügung.
2. Ausführen von relationalen Abfragen ¶
Am einfachsten führt man eine relationale Abfrage aus, indem man eine der eben erwähnten relationalen Eigenschaften eines AR-Objekts ausliest. Falls es sich um den ersten Zugriff handelt, wird automatisch eine weitere Abfrage (gefiltert nach dem Primärschlüssel der AR-Instanz) auf die verknüpfte Tabelle durchgeführt. Das Ergebnis wird dann in Form einer (oder mehrerer) AR-Instanz (bzw. Instanzen) in der entsprechenden Eigenschaft gespeichert. Man spricht hier auch von lazy loading (träges Nachladen), da die Abfrage erst bei Zugriff auf die relationale Eigenschaft erfolgt. Hier ein Beispiel:
// Frage den Beitrag mit der ID 10 ab
$post=Post::model()->findByPk(10);
// Frage den Autor des Beitrags ab: Hier wird eine relationale Abfrage durchgeführt
$author=$post->author;Info: Wurden keine verknüpften Einträge gefunden, so ist die entsprechende relationale Eigenschaft entweder
null(fürBELONGS_TO- undHAS_ONE-Beziehungen) oder ein leeres Array (fürHAS_MANY- undMANY_MANY-Beziehungen). Beachten Sie bitte auch, dass Sie beiHAS_MANY- undMANY_MANY-Beziehungen die relationalen Eigenschaften in einer Schleife durchlaufen müssen, um auf die verknüpften AR-Objekte zugreifen zu können. Andernfalls erhalten Sie die typische "Trying to get property of non-object"-Fehlermeldung.
Mit der lazy loading-Methode lässt es sich bequem arbeiten. Allerdings ist
sie nicht immer sehr effizient. Wollte man zum Beispiel auf die
author-Information von N Posts zugreifen, müssten N relationale
Abfragen durchgeführt werden. Hier bietet sich daher stattdessen die
sogenannte eager loading-Methode (sinngem.: begieriges Laden) an.
Beim Eager loading werden die verknüpften AR-Instanzen gemeinsam mit dem
Hauptobjekt abgefragt. Dazu muss man einem find-
oder findAll-Aufruf lediglich einen
with()-Aufruf voranstellen:
$posts=Post::model()->with('author')->findAll();Das Ergebnis ist ein Array von Post-Objekten, bei denen jeweils - anders als beim
lazy loading bereits vor dem ersten Zugriff - die author-Eigenschaft mit
der verknüpften User-Instanz befüllt wurde. Anstatt für jeden Post eine
weitere Abfrage durchzuführen, liefert der eager loading-Ansatz sämtliche
Beiträge zusammen mit ihren Autorne in einer einzigen JOIN-Abfrage zurück.
Die with()-Methode akzeptiert auch mehrere Beziehungsnamen, die dann alle auf einmal abgefragt werden. Mit diesem Aufruf erhält man zum Beispiel alle Beiträge inklusive ihrer Autoren und Kategorien:
$posts=Post::model()->with('author','categories')->findAll();Man kann eager loading sogar verschachteln. Dazu werden die Beziehungsnamen
in hierarchischer Form an die with()-Methode übergeben:
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->findAll();Dieses Beispiel liefert alle Beiträge zusammen mit ihrem Autor und den Kategorien zurück. Zusätzlich wird zu jedem Autor auch gleich sein Profil sowie die Liste aller seiner Beiträge abgefragt.
Eager loading kann auch über die
CDbCriteria::with-Eigenschaft angestoßen werden:
$criteria=new CDbCriteria;
$criteria->with=array(
'author.profile',
'author.posts',
'categories',
);
$posts=Post::model()->findAll($criteria);oder
$posts=Post::model()->findAll(array(
'with'=>array(
'author.profile',
'author.posts',
'categories',
)
));3. Relationale Abfragen ohne verknüpfte Models zu beziehen ¶
Manchmal müssen relationale Abfragen ausgeführt werden, ohne dass Daten
aus den verknüpften Models (Tabellen) benötigt werden. Ein User könnte z.B.
viele Posts (Beiträge) haben. Ein Beitrag kann entweder veröffentlicht sein,
oder sich im Entwurfsmodus befinden, was über das Feld published im
Post-Model festgelegt wird. Nun sei angenommen, man möchte alle Benutzer
abfragen, die einen Beitrag veröffentlicht haben, ohne dass die Beiträge an
sich weiter interessieren. Das erreicht man wie folgt:
$users=User::model()->with(array(
'posts'=>array(
// von posts soll nichts geliefert werden:
'select'=>false,
// aber es sollen nur die Benutzer mit veröffentlichten Beiträgen
// gewählt werden:
'joinType'=>'INNER JOIN',
'condition'=>'posts.published=1',
),
))->findAll();4. Optionen für relationale Abfragen ¶
Wie erwähnt, können bei der Definition einer Beziehung weitere Optionen als Name-Wert-Paare angeben werden, um die zugehörige relationale Abfrage seinen Wünschen anzupassen. Diese Optionen stehen zur Verfügung:
select: Liste der abzufragenden Spalten der verknüpften AR-Klasse. Der Standardwert ist '*', d.h. alle Spalten. Spaltennamen sollten vereindeutigt werden.condition: DieWHEREKlausel, standardmäßig leer. Spaltennamen sollten vereindeutigt werden.params: Parameter (als Name-Wert-Paare), die an die erzeugte SQL Abfrage gebunden werden sollen.on: ZusätzlicheONKlausel, die an die JOIN-Kondition mit einemANDOperator angehängt werden soll. Die Spaltennamen sollten vereindeutigt werden. BeiMANY_MANY-Beziehungen wird diese Option ignoriert.order: DieORDER BYKlausel, standardmäßig leer. Spaltennamen sollten vereindeutigt werden.with: Eine Liste von Relationen, die zusammen mit diesem Objekt geladen werden sollen. Beachten Sie, dass bei falscher Verwendung dieser Option eine Endlosschleife entstehen kann.joinType: Der Typ des JOINs für diese Beziehung. Der Standardwert istLEFT OUTER JOIN.alias: Der Alias für die verknüpfte Tabelle. Mit dem Standardwertnullwird der Beziehungsname als Alias verwendet.together: Ob ein JOIN der verknüpften Tabelle mit der Haupt- bzw. anderen Tabellen erzwungen werden soll. Diese Option ist nur fürHAS_MANYundMANY_MANYvon Bedeutung. Setzt man diesen Wert auffalse, wird eine separate SQL-Abfrage für die verknüpfte Tabelle ausgeführt, wodurch die ganze Abfrage in manchen Fällen beschleunigt wird, da weniger gleiche Daten pro Zeile übertragen werden müssen. Ist die Optiontruewird die verknüpfte Tabelle immer mittels JOIN zusammen mit der Haupttabelle abgefragt, auch wenn diese seitenweise ausgelesen wird (Pagination). Bleibt die Option leer, wird die verbundene Tabelle nur dann zusammen mit der Haupttabelle in einer einzigen Abfrage eingelesen, falls diese keine Seitenblätterung verwendet. Für weitere Informationen lesen Sie bitte auch den Abschnitt "Geschwindigkeit von relationalen Abfragen".join: ZusätzlicheJOIN-Ausdrück, standardmäßig leer. Diese Option ist seit Version 1.1.3 verfügbar.group: DieGROUP BYKlausel, standardmäßig leer. Spaltennamen sollten vereindeutigt werden.having: DieHAVINGKlausel, standarmäßig leer. Spaltennamen sollten vereindeutigt werden.index: Der Spaltenname, deren Wert als Schlüssel für den Array mit relationalen Objekten verwendet werden soll. Wird diese Option nicht gesetzt, wird ein 0-basierter ganzzahliger Index verwendet. Diese Option kann nur fürHAS_MANY- undMANY_MANY-Beziehungen gesetzt werden.scopes: Die anzuwendenden Scopes. Einzelne Scopes können in der Form'scopes'=>'scopeName', mehrere über'scopes'=>array('scopeName1','scopeName2')angegeben werden. Diese Option steht seit Version 1.1.9 zur Verfügung.
Zusätzlich sind beim lazy loading folgende Optionen für bestimmte Beziehungen
verfügbar:
limit: Limit der abzufragenden Zeilen. Kann NICHT mitBELONGS_TOverwendet werden.offset: Offset der abzufragenden Zeilen. Kann NICHT mitBELONGS_TOverwendet werden.through: Name des Models das als Brücke zu den verknüpften Daten dienen soll. Kann nur mitHAS_ONEundHAS_MANYverwendet werden. Diese Option ist seit Version 1.1.7 verfügbar.
Hier sehen Sie am Beispiel der posts-Beziehung in User, wie man einige dieser
Optionen verwenden kann:
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'order'=>'posts.create_time DESC',
'with'=>'categories'),
'profile'=>array(self::HAS_ONE, 'Profile', 'owner_id'),
);
}
}Greift man auf $author->posts zu, erhält man die posts des
author absteigend sortiert nach ihrer creation time (Erstellzeitpunkt).
Außerdem wurden die Kategorien zu jedem Post mit geladen.
5. Vereindeutigung von Spaltennamen ¶
Wenn ein Spaltenname in zwei oder mehr Tabellen auftaucht, die gemeinsam abgefragt werden sollen, so muss dieser Name vereindeutigt werden. Dies geschieht, indem man den Tabellenalias vor den Spaltennamen stellt.
Bei relationalen Abfragen hat die Haupttabelle den festen Alias t, während
alle relationalen Tabellen standardmäßig den Namen der
entsprechenden Beziehung verwenden. Im folgenden Beispiel stehen die
Aliase t und comments für die Tabellen Post und Comment:
$posts=Post::model()->with('comments')->findAll();Nehmen wir nun an, dass es sowohl in Post, als auch in Comment eine
Spalte namens create_time gibt, die den Erstellzeitpunkt des jeweiligen
Eintrags enthält. Wenn man alle Beiträge zusammen mit ihren Kommentaren
abfragen möchten und die Ergebnisse nacheinander nach der Erstellzeit der Beiträge und
der der Kommentare sortieren will, muss create_time wie folgt vereindeutigt
werden:
$posts=Post::model()->with('comments')->findAll(array(
'order'=>'t.create_time, comments.create_time'
));6. Dynamische Optionen für relationale Abfragen ¶
Sowohl beim with()-Aufruf
als auch bei der with-Eigenschaft kann man dynamische Optionen angeben. Diese
überschreiben dann jene Optionen, die fest in
relations() definiert wurden. Möchte man zum
Beispiel beim obigen User-Model per eager loading gemeinsam alle Beiträge in
aufsteigender Reihenfolge abfragen, kann man die order-Option wie folgt
überschreiben:
User::model()->with(array(
'posts'=>array('order'=>'post.create_time ASC'),
'profile',
))->findAll();Auch beim lazy loading kann man dynamisch Optionen
überschreiben, indem man den Beziehungsnamen als Methode aufruft, und die
dynamischen Optionen als Parameter übergibt. Dieser Aufruf liefert zum
Beispiel alle Beiträge mit status 1 eines Benutzers:
$user=User::model()->findByPk(1);
$posts=$user->posts(array('condition'=>'status=1'));7. Geschwindigkeit von relationalen Abfragen ¶
Wie erwähnt bietet sich der eager loading-Ansatz für Fälle an, in denen auf viele
verknüpfte Objekte zugegriffen werden muss. Er erzeugt einen langen komplizierten
SQL-Ausdruck in dem alle benötigten Tabellen mit JOIN eingebunden werden.
In vielen Fällen ist ein solcher langer SQL-Ausdruck vorzuziehen, da es damit
einfacher wird, nach Spalten in verbundenen Tabellen zu filtern. In einigen
Fällen kann das jedoch auch uneffizient werden.
Angenommen, man möchte die letzten Blogbeiträge zusammen mit den verknüpften Kommentaren abfragen. Falls jeder Beitrag 10 Kommentare hat, enthielten viele Ergebniszeilen redundante Daten. Mit jedem Beitragskommentar würden nämlich die selben Beitragsdaten nochmal übermittelt werden. Ein anderer Ansatz wäre daher, zunächst die letzten Blogbeiträge und danach erst die zugehörigen Kommentare abzufragen. Dafür werden zwar zwei SQL-Abfragen benötigt, allerdings mit dem Vorteil, keine redundanten Daten mehr übertragen zu müssen.
Welche Methode ist nun effizienter? Darauf gibt es keine endgültige Antwort. Eine einzelne große SQL-Abfrage kann schneller sein, da die Datenbank weniger zusätzliche Zeit für das Analysieren und Ausführen einzelner SQL-Abfragen benötigt. Andererseits führt ein großer SQL-Ausdruck zu mehr redundanten Daten und benötigt daher mehr Zeit diese zu übertragen und zu verarbeiten.
Um je nach Bedarf zwischen beiden Varianten wählen zu können, bietet Yii die
together-Option. Standardmäßig verwendet Yii eager loading, generiert also
einen einzelnen SQL-Ausdruck. Es sei denn, das Haupt-Model wurde per LIMIT
begrenzt. Wird die together-Option bei der Definition einer Beziehung
auf true gesetzt, wird ein einzelner SQL-Ausdruck erzwungen, selbst wenn
LIMIT angewendet wurde. Setzt man dieses Flag auf false, werden einige
Tabellen über gesonderte SQL-Abfragen eingelesen. Will man also zum Beispiel
gesonderte SQL-Abfragen verwenden um jeweils die letzten Blogbeiträge sowie
deren Kommentaren einzulesen, kann man die Beziehung comments in Post
so definieren:
public function relations()
{
return array(
'comments' => array(self::HAS_MANY, 'Comment', 'post_id', 'together'=>false),
);
}Man kann diese Option auch dynamisch beim eager loading setzen:
$posts = Post::model()->with(array('comments'=>array('together'=>false)))->findAll();8. Statistische Abfragen ¶
Neben den oben beschriebenen relationalen Abfragen unterstützt Yii auch sogenannte
statistische (auch: aggregierte) Abfragen. Damit können statistische
Informationen über verknüpfte Objekte abgefragt werden, wie
z.B. die Anzahl von Kommentaren zu einem Beitrag, die durchschnittliche
Bewertung eines Produkts, etc. Statistische Abfragen können nur mit
HAS_MANY- (z.B. ein Beitrag hat viele Kommentare) oder einer
MANY_MANY-Beziehungen (z.B. ein Beitrag gehört zu
vielen Kategorien und eine Kategorie hat viele Beiträge) verwendet werden.
Statistische Abfragen werden ähnlich wie relationale Abfrage durchgeführt und müssen analog zunächst in relations() definiert werden:
class Post extends CActiveRecord
{
public function relations()
{
return array(
'commentCount'=>array(self::STAT, 'Comment', 'post_id'),
'categoryCount'=>array(self::STAT, 'Category', 'post_category(post_id, category_id)'),
);
}
}Damit werden zwei statistische Abfragen angegeben: commentCount errechnet die
Anzahl der Kommentare zu einem Beitrag und categoryCount die Anzahl von
Kategorien, denen ein Beitrag zugeordnet wurde. Beachten Sie, dass Post und
Comment in einer HAS_MANY-Beziehung zueineander stehen, während Post und
Category über eine MANY_MANY-Beziehung (über die Tabelle post_category)
verknüpft sind.
So deklariert kann man über $post->commentCount die Anzahl der Kommentare
eines Beitrags auslesen. Beim ersten Zugriff auf diese Eigenschaft wird
dazu implizit eine SQL-Abfrage durchgeführt. Dies entspricht wieder dem
bereits bekannten lazy loading-Ansatz. Soll die Anzahl der Kommentare für
mehrere Beiträge bestimmt werden, kann man stattdessen auch die
eager loading-Methode verwenden:
$posts=Post::model()->with('commentCount', 'categoryCount')->findAll();Dieser Befehl führt drei SQL-Anweisungen aus um alle Beiträge zusammen mit der Anzahl
ihrer Kommentare und Kategorien zurückzuliefern. Würden man den lazy
loading-Ansatz verwenden, würde das bei N Beiträgen in 2*N+1 SQL-Abfragen resultieren.
Standardmäßig wird bei einer statistische Abfrage ein COUNT-Ausdruck
berechnet (und damit in obigem Beispiel die Anzahl der Kommentare und
Kategorien). Man kann auch dies über zusätzliche Beziehungsoptionen in
relations() anpassen. Diese Optionen stehen zur
Verfügung:
select: Der statistische Ausdruck. Vorgabewert istCOUNT(*), was der Anzahl der Kindobjekte entspricht.defaultValue: Standardwert für Zeilen, deren statistische Abfrage "leer" ist. Hat ein Beitrag z.B. keine Kommentare, würde seincommentCountdiesen Wert erhalten. Vorgabewert ist 0.condition: DieWHERE-Bedingung. Standardmäßig leer.params: Die Parameter, die an die erzeugte SQL-Anweisung gebunden werden sollen. Sie müssen als Array aus Name-Wert-Paare angegeben werden.order: DieORDER BY-Anweisung. Standardmäßig leer.group: DieGROUP BY-Anweisung. Standardmäßig leer.having: DieHAVING-Anweisung. Standarmäßig leer.
9. Relationale Abfragen mit Scopes ¶
Auch relationale Abfragen können mit Scopes kombiniert werden. Dabei unterscheidet man zwei Fälle: Scopes die auf das Hauptobjekt und Scopes die auf die verknüpften Objekte angewendet werden.
Der folgende Code zeigt, wie Scopes mit dem Hauptobjekt verwendet werden:
$posts=Post::model()->veroeffentlicht()->kuerzlich()->with('comments')->findAll();Dies unterscheidet sich kaum vom Vorgehen bei nicht-relationalen Abfragen. Der einzige
Unterschied besteht im zusätzlichen Aufruf von with() nach der Kette von
Scopes. Diese Abfrage würde also die kürzlich veröffentlichten
Beiträge zusammen mit ihren Kommentaren zurückliefern.
Bei verknüpften Objekten können Scopes so verwendet werden:
$posts=Post::model()->with('comments:kuerzlich:freigegeben')->findAll();
// oder seit 1.1.7
$posts=Post::model()->with(array(
'comments'=>array(
'scopes'=>array('kuerzlich','freigegeben')
),
))->findAll();
// oder seit 1.1.7
$posts=Post::model()->findAll(array(
'with'=>array(
'comments'=>array(
'scopes'=>array('kuerzlich','freigegeben')
),
),
));Diese Abfrage liefert alle Beiträge zusammen mit ihren freigegebenen
Kommentaren zurück. Beachten Sie, dass comments sich auf den Namen der
Beziehung bezieht, während kuerzlich und freigegeben zwei Scopes
sind, die in der Modelklasse Comment deklariert sind. Beziehungsname und
Scopes sollten durch Doppelpunkte getrennt werden.
Scopes können auch in den with-Optionen in CActiveRecord::relations()
angegeben werden. So würde man im folgenden Beispiel bei Zugriff auf
$user->posts, alle freigegebenen Kommentare eines Beitrags erhalten.
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'with'=>'comments:freigegeben'),
);
}
}
// oder seit 1.1.7
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'author_id',
'with'=>array(
'comments'=>array(
'scopes'=>'freigegeben'
),
),
),
);
}
}Hinweis: Vor Version 1.1.7 konnten bei relationalen Abfragen können nur Scopes verwendet werden, die in CActiveRecord::scopes definiert wurden. Man konnte daher keine parametrisierten Scopes verwenden.
Seit Version 1.1.17 kann man auch bei verknüpften Objekten Scopes mit
Parametern verwenden. Hat Post zum Beispiel einen Scope bewertung der eine
Minimalbewertung als Parameter erwartet, kann man ihn von User wie folgt
verwenden:
$users=User::model()->findAll(array(
'with'=>array(
'posts'=>array(
'scopes'=>array(
'bewertung'=>5,
),
),
),
));10. Relationale Abfragen mit through ¶
Verwendet man through, sollte eine Beziehung wie folgt definiert sein:
'comments'=>array(self::HAS_MANY, 'Comment', array('key1'=>'key2'), 'through'=>'posts')Hierbei ist
key1in der Tabellepostsenthaltenkey2in der KlasseCommentdefiniert
through kann mit HAS_ONE und HAS_MANY verwendet werden.
Through mit HAS_MANY
HAS_MANY through ER
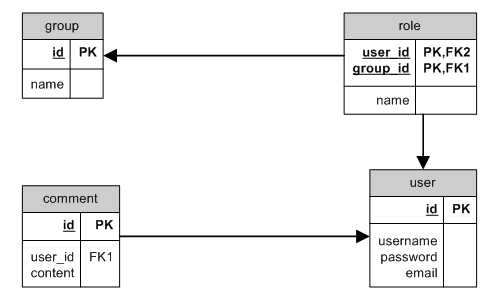
Ein Beispiel für HAS_MANY mit through sind Benutzer in einer bestimmten
Gruppe, falls ein Benutzer über Rollen zu einer Gruppe hinzugefügt wird.
Ein komplizierteres Beispiel wären alle Kommenatre für Benutzer in einer
bestimmten Gruppe zu beziehen. In diesem Fall müssen mehrere Beziehungen mit
through in einem einzelnen Model verwendet werden:
class Group extends CActiveRecord
{
...
public function relations()
{
return array(
'roles'=>array(self::HAS_MANY,'Role','group_id'),
'users'=>array(self::HAS_MANY,'User',array('user_id'=>'id'),'through'=>'roles'),
'comments'=>array(self::HAS_MANY,'Comment',array('id'=>'user_id'),'through'=>'users'),
);
}
}Verwendungsbeispiele
// Alle Gruppen mit allen zugehörigen Usern beziehen:
$groups=Group::model()->with('users')->findAll();
// Alle Gruppen mit allen zugehörigen Usern und Rollen beziehen
$groups=Group::model()->with('roles','users')->findAll();
// Alle User und Rollen beziehen, deren Group-ID 1 ist
$group=Group::model()->findByPk(1);
$users=$group->users;
$roles=$group->roles;
// Alle Kommentare beziehen, deren Group-ID 1 ist
$group=Group::model()->findByPk(1);
$comments=$group->comments;Through mit HAS_ONE
HAS_ONE through ER
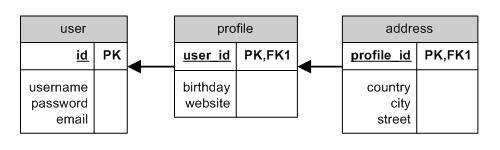
Ein Beispiel für HAS_ONE mit through wären User-Adressen, die über ein
Profil an User gebunden sind. All diese Einheiten (User, Profil und Adresse)
haben entsprechende Models:
class User extends CActiveRecord
{
...
public function relations()
{
return array(
'profile'=>array(self::HAS_ONE,'Profile','user_id'),
'address'=>array(self::HAS_ONE,'Address',array('id'=>'profile_id'),'through'=>'profile'),
);
}
}Verwendungsbeispiele
// Adresse für den User mit ID 1 beziehen
$user=User::model()->findByPk(1);
$address=$user->address;through auf sich selbst
through kann mit einem Model angewendet werden, dass per Brückenmodel auf
sich selbst verweist. Im folgenden Beispiel unterrichten manche User andere
User:
through self ER
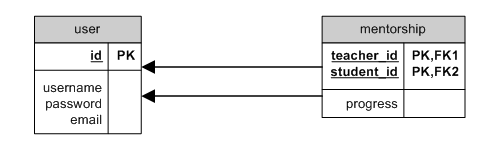
In diesem Fall können Beziehungen wie folgt definiert werden:
class User extends CActiveRecord
{
...
public function relations()
{
return array(
'mentorships'=>array(self::HAS_MANY,'Mentorship','teacher_id','joinType'=>'INNER JOIN'),
'students'=>array(self::HAS_MANY,'User',array('student_id'=>'id'),'through'=>'mentorships','joinType'=>'INNER JOIN'),
);
}
}Verwendungsbeispiele
// Alle Schüler die von Lehrer mit ID 1 unterrichtet werden
$teacher=User::model()->findByPk(1);
$students=$teacher->students;
Found a typo or you think this page needs improvement?
Edit it on github !
Signup or Login in order to comment.