Guia Definitivo do Yii 1.1
0 follower
Active Record Relacional
Nós já vimos como utilizar Active Record (AR) para selecionar dados de uma tabela em um banco de dados. Nessa seção, descrevemos como utilizar AR para acessar registros relacionados em diversas tabelas e como recuperar esse conjunto de dados.
Para utilizar o AR de forma relacional, é necessário que as relações entre chaves primárias e estrangeiras estejam bem definidas entre as tabelas que farão parte do relacionamento.
Nota: A partir da versão 1.0.1, você pode utilizar AR relacional mesmo que você não tenha definido nenhuma chave estrangeira em suas tabelas.
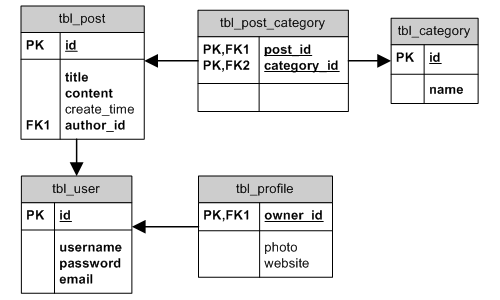
Para simplificar, os exemplos desta seção serão baseados na estrutura de tabelas exibida no seguinte diagrama de entidade-relacionamento:
ER Diagram
Informação: O suporte à chaves estrangeiras é diferente dependendo do SGBD.
O SQLite não tem suporte chaves estrangeiras, mas mesmo assim você pode declara-las quando estiver criando as tabelas. O AR é capaz de tirar proveito dessas declarações para efetuar corretamente as consultas relacionais.
O MySQL suporta chaves estrangeiras apenas utilizando a engine InnoDB. Por isso recomendamos utilizar InnoDB em seus bancos de dados MySQL. Quando utilizar a engine MyISAM, você pode utilizar o seguinte truque para realizar consultas relacionais utilizando AR:
CREATE TABLE Foo ( id INTEGER NOT NULL PRIMARY KEY ); CREATE TABLE bar ( id INTEGER NOT NULL PRIMARY KEY, fooID INTEGER COMMENT 'CONSTRAINT FOREIGN KEY (fooID) REFERENCES Foo(id)' );No código acima, utilizamos a palavra-chave
COMMENTpara descrever a chave estrangeira. O AR pode ler oCOMMENTe reconhecer o relacionamento descrito nele.
1. Declarando Relacionamentos ¶
Antes de utilizar AR para executar consultas relacionais, precisamos fazer com que uma classe AR saiba que está relacionada a outra.
O relacionamento entre duas classes AR está diretamente relacionado com o
relacionamento entre as tabelas no banco, representadas pelas classes.
Do ponto de vista do banco de dados, um relacionamento entre duas tabelas, A e
B, pode ser de três tipos: um-para-muitos (exemplo, User e Post), um-para-um
(exemplo, User e Profile) e muitos-para-muitos (exemplo, Category e Post).
No AR, existem 4 tipos de relacionamentos:
BELONGS_TO: se o relacionamento entre as tabelas A e B for um-para-muitos, então B pertence a A. (por exemplo,Postpertence aUser);HAS_MANY: se o relacionamento entre as tabelas A e B for um-para-muitos, então A tem vários B (por exemplo,Usertem váriosPost);HAS_ONE: esse é um caso especial deHAS_MANY, onde A tem no máximo um B. (por exemplo,Usertem no máximo umProfile);MANY_MANY: corresponde ao relacionamento muitos-para-muitos. É necessária uma terceira tabela associativa para quebrar o relacionamento muitos-para-muitos em relacionamentos um-para-muitos, já que a maioria dos bancos de dados não suporta esse tipo de relacionamento. No diagrama de entidade-relacionamento, a tabelaPostCategorytem essa finalidade. Na terminologia AR, podemos explicar o tipoMANY_MANYcomo a combinação doBELONGS_TOcom umHAS_MANY. Por exemplo,Postpertence a váriasCategoryeCategorytem váriosPost.
A declaração de relacionamentos no AR é feita sobrescrevendo o método relations() da classe CActiveRecord. Esse método retorna um vetor com as configurações do relacionamento. Cada elemento do vetor representa um relacionamento com o seguinte formato:
'NomeRel'=>array('TipoDoRelacionamento', 'NomeDaClase', 'ChaveEstrangeira', ...opções adicionais)Onde NomeRel é o nome do relacionamento; TipoDoRelacionamento especifica o
tipo do relacionamento, que pode ser uma dessas quatro constantes:
self::BELONGS_TO, self::HAS_ONE, self::HAS_MANY e
self::MANY_MANY; NomeDaClasse é o nome da classe AR relacionada com essa classe;
e ChaveEstrangeira especifica a(s) chave(s) estrangeira(s) envolvidas no relacionamento.
Opções adicionais podem ser especificadas ao final de cada vetor de relacionamento
(a ser explicado).
O código a seguir mostra como declaramos os relacionamentos para as classes User
e Post:
class Post extends CActiveRecord
{
public function relations()
{
return array(
'author'=>array(self::BELONGS_TO, 'User', 'authorID'),
'categories'=>array(self::MANY_MANY, 'Category', 'PostCategory(postID, categoryID)'),
);
}
}
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID'),
'profile'=>array(self::HAS_ONE, 'Profile', 'ownerID'),
);
}
}Informação: Uma chave estrangeira pode ser composta, consistindo de duas ou mais colunas. Nesse caso, devemos concatenar os nomes das colunas da chave estrangeira e separa-los por um espaço ou uma vírgula. Para relacionamentos do tipo
MANY_MANY, a tabela associativa também deve ser especificada na chave estrangeira. Por exemplo, o relacionamentocategoriesemPosté especificado com a chave estrangeiraPostCategory(postID, categoryID).
A declaração de relacionamentos em uma classe AR adiciona, implicitamente,
uma propriedade para cada relacionamento declarado. Depois que a consulta
relacional for executada, a propriedade correspondente será preenchida com as
instâncias AR relacionadas. Por exemplo, se $author representa uma instância
de User, podemos utilizar $author->posts para acessar as instâncias de seus
Post relacionados.
2. Executando Consultas Relacionais ¶
A maneira mais simples de executar uma consulta relacional é acessar uma propriedade relacional em uma instância AR. Se a propriedade não foi acessada antes, uma consulta relacional será iniciada, que irá unir as duas tabelas relacionadas e filtra-las pela chave primária da instância. O resultado da consulta será armazenado na propriedade como instância(s) da classe AR relacionada. Essa técnica é conhecida por de lazy loading (carregamento retardado). Ou seja, a pesquisa relacional é executada somente quando os objetos relacionados são acessados. O exemplo abaixo mostra como utilizar essa técnica:
// recupera post com ID 10
$post=Post::model()->findByPk(10);
// recupera o autor do post. Uma consulta relacional será executada aqui
$author=$post->author;Informação: Se não existirem instâncias para um relacionamento, a propriedade correspondente poderá ser null ou um vetor vazio. Para relacionamentos do tipo
BELONGS_TOeHAS_ONE, o retorno é null; paraHAS_MANYeMANY_MANY, o retorno é um vetor vazio. Note queHAS_MANYeMANY_MANYretornam um vetor de objetos. Sendo assim, você precisará primeiro acessar seus elementos para acessar suas propriedades. Caso contrário, você poderá gerar o erro "Trying to get property of non-object".
A técnica do lazy loading é bastante conveniente, mas não é eficiente em alguns
cenários. Por exemplo, se queremos acessar informações do autor para N
posts, a utilização de lazy loading irá executar N consultas. Nessas circunstâncias
devemos recorrer a técnica de eager loading.
Nessa técnica, recuperamos as instâncias AR relacionadas junto com a instância AR principal. Isso é feito utilizando-se o método with(), junto com um dos métodos find ou findAll. Por exemplo:
$posts=Post::model()->with('author')->findAll();O código acima retornará um vetor de instâncias de Post. Diferente do lazy
loading, a propriedade author de cada instância de Post já está preenchida
com a instância de User relacionada, antes de acessarmos a propriedade. Em vez
de executar uma consulta de junção para cada post, a técnica de eager loading
traz todos os posts, junto com seus autores, em uma única consulta.
Podemos especificar o nome de múltiplos relacionamentos na chamada do método with() e o eager loading se encarregará de traze-los todos de uma só vez. Por exemplo, o código a seguir irá recuperar todos os posts, juntos com seus autores e suas categorias:
$posts=Post::model()->with('author','categories')->findAll();Podemos também fazer eager loadings aninhados. Em vez de uma lista com nomes de relacionamentos, podemos passar uma representação hierárquica de nomes de relacionamentos para o método with(), como no exemplo a seguir:
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->findAll();O exemplo acima irá recuperar todos os posts, junto com seus autores e suas categorias. Ele trará também o perfil de cada autor e seus posts.
Nota: O uso do método with() foi alterado a partir da versão 1.0.2. Por favor, leia a documentação correspondente cuidadosamente.
A implementação do AR no Yii é bastante eficiente. Quando utilizamos eager loading
para carregar uma hierarquia de objetos relacionados envolvendo N relacionamentos
do tipo HAS_MANY e MANY_MANY, serão necessárias N+1 consultas SQL para obter
os resultados necessários. Isso significa que serão executadas 3 consultas SQL no
último exemplo, por causa das propriedade posts e categories. Outros frameworks
preferem uma técnica mais radical, utilizando somente uma consulta. A primeira vista,
essa técnica parece mais eficiente porque menos consultas estão sendo executadas
pelo banco de dados. Mas nas realidade, isso é impraticável por duas razões.
Primeira, existem muitas colunas com dados repetidos nos resultados, que precisam de
mais tempo para serem transmitidos e processados. Segunda, o número de registros em
um resultado cresce exponencialmente de acordo com o número de tabelas envolvidas,
de forma a ficarem simplesmente intratáveis quanto mais relacionamentos estão envolvidos
A partir da versão 1.0.2, você também pode forçar que a consulta relacional seja feita com uma única consulta SQL. Simplesmente adicione uma chamada ao método together() depois do método with(). Por exemplo:
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->together()->findAll();A consulta acima será executada em um único comando SQL. Sem o método together,
serão necessárias três consultas: uma irá fazer a junção das tabelas Post, User
e Profile, outra irá fazer a junção de User e Post e a última irá fazer a junção de
Post, PostCategory e Category.
3. Opções de Consultas Relacionais ¶
Nós mencionamos que pode-se especificar algumas opções adicionais na declaração de um relacionamento. Essas opções, especificadas na forma de pares nome-valor, são utilizadas para personalizar as consultas relacionais. Elas estão resumidas abaixo:
select: uma lista de colunas que serão selecionadas nas classes AR relacionadas. Por padrão, seu valor é '*', que significa todas as colunas. Quando utilizada em expressões os nomes das colunas devem se identificados com umaliasToken(apelido para tabela), (por exemploCOUNT(??.name) AS nameCount).condition: representa a cláusulaWHERE. Não tem nenhum valor por padrão. Note que, para evitar conflitos entre nomes de colunas iguais, referencias a colunas precisão ser identificadas por umaliasToken, (por exemplo,??.id=10).params: os parâmetros que serão vinculados ao comando SQL gerado. Eles devem ser informados em um vetor, com pares de nome-valor. Essa opção está disponível desde a versão 1.0.3.on: representa a cláusulaON. A condição especificada aqui será adicionada à condição de junção, utilizando-se o operadorAND. Note que, para evitar conflitos entre nomes de colunas iguais, os nomes delas devem ser diferenciados com a utilização de umaliasToken, (por exemplo,??.id=10). Essa opção não pode ser utilizada em relações do tipoMANY_MANY. Ela está disponível desde a versão 1.0.2.order: representa a cláusulaORDER BY. Não tem nenhum valor por padrão. Note que, para evitar conflitos entre nomes de colunas iguais, referencias a colunas precisão ser identificadas por umaliasToken, (por exemplo,??.age DESC).with: uma lista de objetos filhos relacionados que deverão ser carregados juntos com esse objeto. Seja cuidadoso, pois utilizar esta opção de forma inapropriada poderá gerar um loop infinito nos relacionamentos.joinType: o tipo de junção nesse relacionamento. Por padrão éLEFT OUTER JOIN.aliasToken: é o marcador do prefixo da coluna. Ele será substituído pelo apelido da tabela correspondente para diferenciar as referencias às colunas. Seu padrão é'??.'.alias: o apelido para a tabela associada a esse relacionamento. Essa opção está disponível desde a versão 1.0.1. Por padrão é null, indicando que o apelido para a tabela será gerado automaticamente. Um alias é diferente de umaaliasToken, uma vez que esse último é só um marcador que será substituído pelo verdadeiro apelido para a tabela.together: especifica se a tabela associada com esse relacionamento deverá ser forçada a juntar-se a tabela primária. Essa opção só faz sentido em relacionamentos do tipoHAS_MANYeMANY_MANY. Se está opção não for utilizada, ou seu valor for false, cada relacionamentoHAS_MANYeMANY_MANYterão suas próprias instruções JOIN, para aumentar a performance. Essa opção está disponível desde a versão 1.0.3.group: representa a cláusulaGROUP BY. Não tem nenhum valor por padrão. Note que, para evitar conflitos entre nomes de colunas iguais, referencias a colunas precisão ser identificadas por umaliasToken, (por exemplo,??.age).having: representa a cláusulaHAVING. Não tem nenhum valor por padrão. Note que, para evitar conflitos entre nomes de colunas iguais, referencias a colunas precisão ser identificadas por umaliasToken, (por exemplo,??.age DESC). Esta opção está disponível desde a versão 1.0.1.index: o nome de uma coluna cujos valores devem ser utilizados como chaves no vetor que retorna os objetos relacionados. Sem a utilização dessa opção, o vetor retornado tem índices numéricos iniciando em 0. Esta opção só pode ser utilizada em relacionamentos do tipoHAS_MANYeMANY_MANY. Ela está disponível desde a versão 1.0.7.
Além dessas, as opções abaixo podem ser utilizadas para certos relacionamentos quando utilizado o lazy loading:
limit: limite de registros a ser selecionado. Essa opção NÂO pode ser utilizada em relacionamentos do tipoBELONGS_TO.offset: posição, em relação aos resultados encontrados, que os registros serão selecionados. Essa opção NÂO pode ser utilizada em relacionamentos do tipoBELONGS_TO.
Abaixo alteramos a declaração do relacionamento posts em User, incluindo algumas
das opções descritas acima:
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID',
'order'=>'??.createTime DESC',
'with'=>'categories'),
'profile'=>array(self::HAS_ONE, 'Profile', 'ownerID'),
);
}
}Agora, se acessarmos $author->post, obteremos os posts desse autor, ordenados
pela sua data de criação em ordem descendente. Cada instância de post virá com
suas categorias já carregadas.
Informação: Quando o nome de uma coluna aparece em duas ou mais tabelas em uma junção, eles precisam ser diferenciados. Isso é feito prefixando-se o nome da tabela ao nome da coluna. Por exemplo,
idse tornaTeam.id. Entretanto, nas consultas relacionais utilizando AR, não temos essa liberdade porque as instruções de relacionamentos são geradas automaticamente pelo Active Record, que dá a cada tabela um apelido (alias). Por isso, para evitar evitar conflitos entre nomes de colunas devemos utilizar um marcador para identificar a existência de uma coluna que precisa ser diferenciada. O AR irá substituir esse marcador pelo apelido da tabela, diferenciando apropriadamente a coluna.
4. Opções Dinâmicas em Consultas Relacionais ¶
A partir da versão 1.0.2, podemos utilizar opções dinâmicas em consultas relacionais
, tanto no método with() quanto na opção with.
As opções dinâmicas irão sobrescrever as opções existentes, declaradas no método
relations(). Por exemplo, com o modelo User acima, podemos
utilizar eager loading para retornar os posts de um determinado autor em ordem
crescente (a opção order especificada na relação utiliza ordem decrescente),
como no exemplo abaixo:
User::model()->with(array(
'posts'=>array('order'=>'??.createTime ASC'),
'profile',
))->findAll();A partir da versão 1.0.5, opções dinâmicas também podem ser utilizadas com o
lazy loading. Para isso, devemos chamar o método cujo nome é o mesmo da relação e
passar os opções dinâmicas como parâmetros para ele. Por exemplo, o código a seguir
retorna os posts de um usuário cujo status é 1:
$user=User::model()->findByPk(1);
$posts=$user->posts(array('condition'=>'status=1'));5. Consultas Estatísticas ¶
Nota: Consultas estatísticas são suportadas a partir da versão 1.0.4.
Além das consultas relacionais descritas acima, o Yii também suporta as chamadas
consultas estatísticas (statistical query, ou aggregational query). Essas consultas
retornam informações agregadas sobre objetos relacionados, tais como o número de
comentários em cada post, a avaliação média para cada produto, etc. Consultas
estatísticas só podem ser utilizadas em objetos relacionadas com HAS_MANY (por
exemplo, um post tem vários comentários) ou MANY_MANY (por exemplo, um post
pertence a várias categorias e uma categoria tem vários posts).
Executar consultas estatísticas é bem parecido com a execução de consultas relacionais que descrevemos anteriormente. Primeiro precisamos declarar o consulta estatística no método relations() da classe CActiveRecord, como fazemos com as consultas relacionais.
class Post extends CActiveRecord
{
public function relations()
{
return array(
'commentCount'=>array(self::STAT, 'Comment', 'postID'),
'categoryCount'=>array(self::STAT, 'Category', 'PostCategory(postID, categoryID)'),
);
}
}No código acima, declaramos duas consultas estatísticas: commentCount, que
calcula o número de comentários em um post e categoryCount, que calcula o
número de categorias a quem um post pertence. Note que o relacionamento entre
Post e Comment é do tipo HAS_MANY, enquanto o relacionamento entre Post
e Category é MANY_MANY (com a tabela associativa PostCategory). Como podemos
ver a declaração é bastante similar a das relações descritas anteriormente. A única
diferença é que o tipo de relação agora é STAT.
Com a declaração acima, podemos recuperar o número de comentários para um post
acessando a propriedade $post->commentCount. Ao acessá-la pela primeira vez,
uma instrução SQL será executada, implicitamente, para retornar o resultado
correspondente. Como já sabemos, essa técnica é chamada de lazy loading. Também
podemos utilizar a técnica eager loading se precisarmos determinar a quantidade
de comentários para vários posts.
$posts=Post::model()->with('commentCount', 'categoryCount')->findAll();O código acima irá executar três instruções SQL para retornar todos os posts
juntamente com a quantidade de comentários e categorias em cada um deles.
Utilizando lazy loading, acabaríamos executando 2*N+1 instruções SQL, se
existirem N posts.
Por padrão, uma consulta estatística utiliza a expressão COUNT para calcular
os resultados. Podemos personaliza-la especificando opções adicionais, no método
relations(). As opções disponíveis estão resumidas abaixo:
select: a expressão estatística. Por padrão éCOUNT(*), que contará todos os objetos.defaultValue: o valor a ser atribuído aos registros que não receberem um resultado em uma consulta estatística. Por exemplo, se um post não tiver comentários, o valor decommentCountserá o especificado nesta propriedade. Por padrão, seu valor é 0.condition: representa a clásulaWHERE. Não tem nenhum valor por padrão.params: representa os parâmetros que devem ser vinculados na instrução SQL gerada. Deve ser um vetor com pares nome-valor.order: representa a cláusulaORDER BY. Não tem nenhum valor por padrão.group: representa a cláusulaGROUP BY. Não tem nenhum valor por padrão.having: representa a cláusulaHAVING. Não tem nenhum valor por padrão.
6. Consultas Relacionais Utilizando Named Scopes ¶
Nota: O suporte a named scopes está disponível a partir da versão 1.0.5.
As consultas relacionais também podem ser utilizadas em conjunto com named scopes. Isso pode ser feito de duas formas. Na primeira, os named scopes são aplicados aos modelos principais. Na segunda forma os named scopes são aplicados aos modelos relacionados.
No código a seguir vemos como aplicar named scopes no modelo principal:
$posts=Post::model()->published()->recently()->with('comments')->findAll();Vemos que é bem parecido com a forma não-relacional. A única diferença é
uma chamada ao método with() após a cadeia de named scopes. Essa consulta
retornará os posts publicados recentemente, junto com seus comentários.
O código a seguir mostra como aplicar named scopes em objetos relacionados.
$posts=Post::model()->with('comments:recently:approved')->findAll();A consulta acima irá retornar todos os posts, junto com os seus comentário aprovados.
Note que comments refere-se ao nome do relacionamento, enquanto recently e approved
referem-se a dois named scopes declarados na classe do modelo Comment. O nome do
relacionamento e os named scopes devem ser separados por dois-pontos (":").
Named scopes também podem ser especificados com a opção with, descrita acima.
No exemplo a seguir, a propriedade $user->posts retorna todos os comentários
aprovados dos posts.
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID',
'with'=>'comments:approved'),
);
}
}Nota: Named scopes aplicados a modelos relacionados devem ser declarados no método CActiveRecord::scopes. Como resultado, eles não podem ser parametrizados.
Found a typo, or you think this page needs improvement?
Edit it on GitHub !
Signup or Login in order to comment.