Das Standardhandbuch für Yii 1.0
0 follower
Relationale ActiveRecords
Wir haben schon gesehen, wie wir ActiveRecord (AR) nutzen können, um Daten einer einzelnen Tabelle auszulesen. In diesem Abschnitt beschreiben wir, wie wir mit AR mehrere relationale Datentabellen zusammenführen, um verbundene Datensätze zurückzuerhalten.
Um mit relationalen AR zu arbeiten, müssen zwischen den zu verbindenden Tabellen eindeutige Fremdschlüsselbeziehungen definiert worden sein. AR stützt sich auf die Metadaten dieser Beziehungen, um zu ermitteln, wie die Tabellen verbunden werden sollen.
Hinweis: Ab Version 1.0.1 können Sie relationale AR auch verwenden, wenn Sie keine Fremdschlüssel-Constraints in ihrer Datenbank definiert haben.
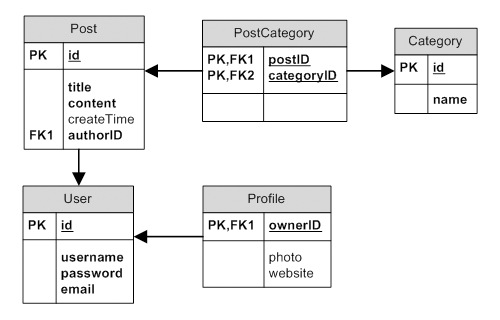
Der Einfachheit halber, verwenden wir zur Veranschaulichung der Beispiel in diesem Abschnitt das folgende ER-Diagramm (engl.: entity relationship, Gegenstands-Beziehungs-Modell).
ER-Diagramm
Info: DBMS unterscheiden sich in ihrer jeweiligen Unterstützung von Fremdschlüssel-Constraints.
SQLite unterstützt keine Fremschlüssel-Constraints, aber Sie können beim Erstellen von Tabellen trotzdem Constraints festlegen. AR kann sich diese Angaben zunutze machen, um relationale Abfragen in richtiger Weise zu unterstützen.
MySQL unterstützt Fremdschlüssel-Constraints mit der InnoDB-Engine, aber nicht mit MyISAM. Es wird deshalb empfohlen, dass Sie InnoDB für MySQL-Datenbanken benutzen. Falls Sie MyISAM verwenden, können Sie relationale Abfragen mit AR mit folgendem Trick durchführen:
CREATE TABLE Foo ( id INTEGER NOT NULL PRIMARY KEY ); CREATE TABLE bar ( id INTEGER NOT NULL PRIMARY KEY, fooID INTEGER COMMENT 'CONSTRAINT FOREIGN KEY (fooID) REFERENCES Foo(id)' );Hier verwenden wir das Schlüsselwort
COMMENT, um die Fremdschlüssel-Constraints zu beschreiben. AR kann diese Informationen auslesen, um die Beziehung zu erkennen.
1. Festlegen der Beziehungen ¶
Bevor wir relationale Abfragen mit AR durchführen können, müssen wir AR bekannt geben, wie eine AR-Klasse mit einer anderen in Beziehung steht.
Die Beziehung zwischen zwei AR-Klassen steht in direktem Zusammenhang mit der
Beziehung zwischen den Datenbanktabellen, die die AR-Klassen repräsentieren.
Aus Sicht der Datenbank gibt es drei Beziehungstypen zwischen zwei
Tabellen A und B: eins-zu-viele (engl.: one-to-many, 1:n, z.B. zwischen User und Post),
eins-zu-eins (engl.: one-to-one, 1:1, z.B. zwischen User und Profile) und
viele-zu-viele (engl.: many-to-many, n:m, z.B. zwischen Category und Post):
BELONGS_TO(gehört zu): Wenn die Beziehung zwischen den Tabellen A und B eins-zu-viele ist, dann gehört B zu A (z.B.Postgehört zuUser).HAS_MANY(hat viele): Wenn die Beziehung zwischen der Tabelle A und B eins-zu-viele ist, dann hat A viele B (z.B.Userhat vielePost).HAS_ONE(hat ein): Dies ist ein Spezialfall vonHAS_MANY, wobei A höchstens ein B hat (z.B.Userhat höchstens einProfile).MANY_MANY(viele viele): Dies entspricht der viele-zu-viele-Beziehung (n:m-Beziehung) bei Datenbanken. Eine Verbindungstabelle wird benötigt, um die viele-zu-viele Beziehung auf eins-zu-viele-Beziehungen herunterzubrechen, da die meisten DBMS viele-zu-viele-Beziehungen nicht direkt unterstützen. In unserem Schema dientPostCategorydiesem Zweck. In AR-Terminologie können wirMANY_MANYals eine Kombination vonBELONGS_TOundHAS_MANYerklären. Beispielsweise gehörtPostzu vielenCategoryundCategoryhat vielePost.
Das Festlegen der Beziehungen geschieht in AR durch Überschreiben der relations()-Methode von CActiveRecord. Die Methode gibt ein Array der Beziehungsstruktur zurück. Jedes Arrayelement repräsentiert eine einzelne Beziehung im folgenden Format:
'VarName'=>array('RelationsTyp', 'KlassenName', 'FremdSchlüssel', ...Zusätzliche Optionen)wobei VarName der Name der Beziehung ist. RelationsTyp spezifiziert den Typ der Beziehung
und kann eine dieser vier Konstanten sein: self::BELONGS_TO, self::HAS_ONE,
self::HAS_MANY und self::MANY_MANY. KlassenName ist der Name der AR-Klasse, die zu
dieser in Beziehung steht. Und FremdSchlüssel gibt den/die an der Beziehung beteiligten
Fremdschlüssel an. Am Ende können zusätzliche Optionen für jede Beziehung angegeben werden
(was später beschrieben wird).
Der folgende Code zeigt, wie wir die Beziehung für die User- und Post-Klasse angeben.
class Post extends CActiveRecord
{
public function relations()
{
return array(
'author'=>array(self::BELONGS_TO, 'User', 'authorID'),
'categories'=>array(self::MANY_MANY, 'Category', 'PostCategory(postID, categoryID)'),
);
}
}
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID'),
'profile'=>array(self::HAS_ONE, 'Profile', 'ownerID'),
);
}
}Info: Ein Fremdschlüssel kann auch ein kombinierter Schlüssel sein, also aus zwei oder mehr Attributen bestehen. In diesem Fall sollten wir die Namen der Fremdschlüssel verketten und durch ein Komma oder Leerzeichen trennen. Beim
MANY_MANYBeziehungstyp muss der Name der Verbindungstabelle beimFremdSchlüsselebenfalls angegeben werden. Zum Beispiel ist der Fremdschlüssel für diecategories-Beziehung inPostmitPostCategory(postID, categoryID)angegeben.
Das Definieren von Beziehungen in einer AR-Klasse fügt dieser implizit eine Eigenschaft
für jede Beziehung hinzu. Nachdem eine relationale Abfrage ausgeführt wurde, ist die
entsprechende Eigenschaft mit der/den verbundenen AR Instanz(en) befüllt.
Steht $author bespielsweise für eine AR-Instanz User, so können wir mit
$author->posts auf die verbundenen Post-Instanzen zugreifen.
2. Ausführen von relationalen Abfragen ¶
Die einfachste Art, relationale Abfragen auszuführen, ist, eine Verbundeigenschaft einer AR-Instanz zu lesen. Falls auf die Eigenschaft noch nicht zugegriffen wurde, wird eine relationale Abfrage ausgeführt, die die beiden betroffenen Tabellen kombiniert und nach dem Primärschlüssel der aktuellen AR-Instanz filtert. Das Abfrageergebnis wird in der Eigenschaft als Instanz(en) der verbundenen AR-Klasse gespeichert. Dies ist unter dem Namen lazy loading-Methode (träges Nachladen) bekannt, d.h. die relationale Abfrage wird erst beim ersten Zugriff auf die Verbundobjekte durchgeführt. Das folgende Beispiel zeigt, wie man dieses Konzept einsetzen kann:
// Frage den Beitrag mit der ID 10 ab
$post=Post::model()->findByPk(10);
// Frage den Autor des Beitrags ab: Hier wird eine relationale Abfrage durchgeführt
$author=$post->author;Info: Wenn es keine verbundene Instanz für die Beziehung gibt, kann die entsprechende Eigenschaft null oder ein leeres Array sein. Für die
BELONGS_TOundHAS_ONEBeziehungen ist das Ergebnis null, fürHAS_MANYundMANY_MANYein leerer Array.
Die lazy loading-Methode ist sehr bequem einzusetzen, aber in einigen Szenarien
nicht sehr effizient. Wenn wir beispielsweise mit der lazy loading-Methode auf
die author-Information von N Posts zugreifen wollen, müssen N relationale
Abfragen durchgeführt werden. Unter diesen Umständen sollten wir auf die so genannte
eager loading-Methode (begieriges Laden) zurückgreifen.
Das eager loading-Konzept fragt die verbundenen AR Instanzen zusammen mit der
AR Hauptinstanz ab. Das wird in AR mit der with()-Methode zusammen
mit der find- oder findAll-Methode
durchgeführt. Zum Beispiel:
$posts=Post::model()->with('author')->findAll();Der obige Code liefert ein Array von Post-Instanzen. Anders als beim
lazy loading-Ansatz ist die author-Eigenschaft in jeder Post-Instanz
schon mit der verbundenen User-Instanz befüllt, bevor wir auf die Eigenschaft zugreifen.
Anstatt für jeden Post eine relationale Abfrage durchzuführen, liefert der
eager loading-Ansatz mit einer einzigen JOIN-Abfrage alle Beiträge zusammen
mit ihren Autoren.
Wir können mehrere Namen von Beziehungen in der with()-Methode
angeben und mit der eager loading-Methode alle in einem Zug zurückerhalten.
Beispielsweise liefert der folgende Code Beiträge zusammen mit ihren Autoren und
Kategorien zurück:
$posts=Post::model()->with('author','categories')->findAll();Wir können auch verschachteltes eager loading ausführen. Anstatt einer Liste
von Beziehungsnamen, können wir der with()-Methode
eine hierarchische Darstellung wie folgt mitgeben:
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->findAll();Das obige Beispiel liefert alle Beiträge zusammen mit ihrem Autor und den Kategorien zurück. Zusätzlich wird auch das Profil sowie alle Beiträge des jeweiligen Autors zurückgegeben.
Hinweis: Die Verwendung der with()-Methode hat sich ab Version 1.0.2 geändert. Bitte lesen Sie die API-Dokumentation sorgfältig durch.
Die AR-Implementierung von Yii ist sehr effektiv. Beim eager loading einer
Hierarchie von N HAS_MANY- oder MANY_MANY-Beziehungen sind N+1
SQL Abfragen erforderlich, um das Ergebnis zu erhalten. Das bedeutet, dass
im letzten Beispiel 3 SQL Abragen für die posts- und categories-Eigenschaften
ausgeführt werden müssen. Andere Frameworks verfolgen eine fundamentalere
Herangehensweise, indem sie nur eine SQL Anweisung benutzen. Auf den ersten Blick
ist dieses fundamentalere Verfahren effizienter, da weniger Anfragen vom DBMS
analysiert und ausgeführt werden müssen. In Wahrheit ist es aber aus zwei Gründen
tatsächlich unpraktisch. Erstens enthält das Ergebnis viele, sich wiederholende
Datenspalten, für deren Übermittlung und Bearbeitung zusätzliche Zeit benötigt wird.
Zweitens wächst mit der Anzahl der beteiligten Tabellen die Anzahl der Spalten
exponentiell und das macht es unübersichtlicher, wenn mehrere Beziehungen daran beteiligt sind.
Seit Version 1.0.2 können sie auch erzwingen, dass die relationale Abfrage mit genau einer SQL Abfrage durchgeführt wird. Fügen Sie einfach einen together()-Aufruf nach with() an, z.B.
$posts=Post::model()->with(
'author.profile',
'author.posts',
'categories')->together()->findAll();Die obige Abfrage wird über eine einzelne SQL-Abfrage ausgeführt. Ohne
den Aufruf von together würden drei SQL Abfragen
benötigt werden: eine für den Verbund der Tabellen Post, User und
Profile, eine, die die Tabellen User und Post verbindet und eine
weitere die Post, PostCategory und Category zusammenführt.
3. Optionen für relationale Abfragen ¶
Wir haben bereits erwähnt, dass bei Beziehungsdeklarationen zusätzliche Optionen angegeben werden können. Diese Optionen, durch Name-Wert-Paare festgelegt, werden verwendet um die relationale Abfrage individuell anzupassen. Sie sind nachfolgend zusammengestellt.
select: Eine Liste der abzufragenden Spalten der betreffenden AR Klasse. Der Standardwert ist '*', d.h. alle Spalten. Die Spaltennamen sollten durchaliasTokeneindeutig gekennzeichnet sein, wenn sie in einem Ausdruck auftreten (z.B.COUNT(??.name) AS nameCount).condition: DieWHEREKlausel, standardmäßig leer. Beachten Sie, dass Spaltenreferenzen mitaliasTokeneindeutig gekennzeichnet werden müssen (z.B.??.id=10).params: Die Parameter, die an die erzeugte SQL Abfrage gebunden werden sollen. Diese sollten als ein Array von Namen-Werte Paaren angegeben werden. Diese Option ist seit Version 1.0.3 verfügbar.on: DieONKlausel. Die hier angegebene Bedingung wird an die JOIN Abfrage mit einemANDOperator angehängt. Die Spaltennamen sollten durchaliasTokeneindeutig gekennzeichnet sein (z.B.??.id=10). BeiMANY_MANY-Beziehungen wird diese Option nicht berücksichtigt. Diese Option ist seit Version 1.0.2 verfügbar.order: DieORDER BYKlausel, standardmäßig leer. Beachten Sie, dass Spaltenreferenzen mitaliasTokeneindeutig gekennzeichnet werden müssen (z.B.??.age DESC).with: Eine Liste kind-bezogener Objekte, die zusammen mit diesem Objekt geladen werden sollen. Beachten Sie, dass bei falscher Verwendung dieser Option eine endlose Beziehungsschleife entstehen kann.joinType: Jointyp für diesen Beziehungstyp. Der Standardwert istLEFT OUTER JOIN.aliasToken: Der Platzhalter für die Spaltenpräfix. Er wird durch den entsprechenden Alias der Tabelle ersetzt, um die Spaltenreferenzen zu vereindeutigen. Der Standardwert ist'??.'alias: Der Alias für die in dieser Beziehung verbundene Tabelle. Diese Option ist seit Version 1.0.1 verfügbar. Der Standardwert ist null, das bedeutet, der Tabellenalias wird automatisch erzeugt. Das ist etwas anderes alsaliasToken. Im letzterem Falle handelt es sich nur um einen Platzhalter, der vom tatsächlichen Tabellenalias ersetzt wird.group: DieGROUP BYKlausel, standardmäßig leer. Beachten Sie, dass Spaltenreferenzen mitaliasTokeneindeutig gekennzeichnet werden müssen (z.B.??.age).having: DieHAVINGKlausel, standarmäßig leer. Beachten Sie, dass Spaltenreferenzen mitaliasTokeneindeutig gekennzeichnet werden müssen (z.B.??.age). Diese Option ist seit Version 1.0.1. verfügbar.index: Der Name der Spalte, deren Wert als Schlüssel für den Array mit relationalen Objekten verwendet werden soll. Wird diese Option nicht gesetzt, wird ein 0-basierter ganzzahliger Index verwendet. Diese Option kann nur fürHAS_MANY- undMANY_MANY-Beziehungen gesetzt werden. Diese Option ist seit Version 1.0.7 verfügbar.
Zusätzlich sind für bestimmte Beziehungen folgende Optionen beim lazy loading
verfügbar:
limit: Begrenzt die auszuwählenden Zeilen. Diese Option ist bei der BeziehungBELONGS_TONICHT anwendbar.offset: Versatz der auszuwählenden Zeilen. Diese Option ist bei der BeziehungBELONGS_TONICHT anwendbar.
Nachfolgend modifizieren wir die posts-Beziehung beim User indem wir einige der
obigen Optionen einbeziehen:
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID',
'order'=>'??.createTime DESC',
'with'=>'categories'),
'profile'=>array(self::HAS_ONE, 'Profile', 'ownerID'),
);
}
}Wenn wir jetzt auf $author->posts zugreifen, erhalten wir die posts des
author absteigend sortiert nach ihrer creation time (Erstellzeitpunkt).
Bei jedem Post wurden auch seine Kategorien geladen.
Info: Wenn ein Spaltenname in zwei oder mehr Tabellen auftaucht, die verbunden werden sollen, muss er eindeutig gekennzeichnet werden. Dies geschieht durch voranstellen des Tabellennamens vor den Spaltennamen. Aus
idwird beispielsweiseTeam.id. Bei relationalen AR-Abfragen haben wir diese Freiheit nicht, da AR den SQL-Ausdruck automatisch erzeugt und jeder Tabelle systematisch ein Alias gegeben wird. Um Konflikte mit Spaltennamen zu vermeiden, benutzen wir daher einen Platzhalter, um zu markieren, dass wir eine zu kennzeichnende Spalte verwenden. AR ersetzt den Platzhalter mit einem geeignet Tablellenalias und sorgt so fur eine ordnungsgemäße eindeutige Kennzeichnung.
4. Dynamische Optionen für relationale Abfragen ¶
Seit Version 1.0.2 können wir dynamische Optionen für relationale Abfragen sowohl bei
with(), als auch bei der with-Option nutzen. Die dynamischen
Optionen überschreiben die in der
relations()-Methode spezifisierten.
Wollen wir beispielsweise im obigen User-Model den eager loading-Ansatz
nutzen, um die Beiträge, die zu einem Autor gehören in aufsteigender
Reihenfolge zu erhalten (die order-Option in der relations-Angabe verwendet
absteigende Reihenfolge), können wir das folgendermaßen erreichen:
User::model()->with(array(
'posts'=>array('order'=>'??.createTime ASC'),
'profile',
))->findAll();Seit Version 1.0.5 können dynamische Abfrageoptionen auch beim lazy
loading-Ansatz verwendet werden. Dazu rufen wir die Methode mit dem namen des
verbundenen Objekts auf und übergeben die Abfrageoptionen als Parameter. Der
folgende Code liefert zum Beispiel die Beiträge eines Benutzers mit status
1:
$user=User::model()->findByPk(1);
$posts=$user->posts(array('condition'=>'status=1'));5. Statistische Abfragen ¶
Hinweis: Statistische Abfragen werden seit Version 1.0.4 unterstützt.
Neben den oben beschriebenen relationalen Abfragen unterstützt Yii auch sogenannte
statistische Abfragen (auch: aggregierte Abfragen, engl.: aggregational query)
Mit ihnen können Informationen zu verbundenen Objekten ausgelesen werden, wie
z.B. die Anzahl von Kommentaren zu einem Beitrag, die durchschnittliche
Bewertung eines Produkts, etc. Statistische Abfragen können nur für Objekte
durchgeführt werden, die in einer HAS_MANY-Beziehung (z.B. ein Beitrag hat
viele Kommentare) oder einer MANY_MANY-Beziehung (z.B. ein Beitrag gehört zu
vielen Kategorien und eine Kategorie hat viele Beiträge) stehen.
Eine statistische Abfrage wird ähnlich wie eine oben beschriebene relatoinale Abfrage durchgeführt. Analog dazu müssen wir zunächst die statistische Abfrage in der relations()-Methode des CActiveRecord festlegen.
class Post extends CActiveRecord
{
public function relations()
{
return array(
'commentCount'=>array(self::STAT, 'Comment', 'postID'),
'categoryCount'=>array(self::STAT, 'Category', 'PostCategory(postID, categoryID)'),
);
}
}Hier legen wir zwei statistische Abfragen fest: commentCount errechnet die
Anzahl der Kommentare zu einem Beitrag und categoryCount die Anzahl von
Kategorien, denen ein Beitrag zugeordnet wurde. Beachten Sie, dass Post und
Comment in einer HAS_MANY-Beziehung zueineander stehen, während Post und
Category über eine MANY_MANY-Beziehung (über die Verbindungstabelle
PostCategory) verknüpft sind.
Mit obiger Deklaration können wir die Anzahl der Kommentare eines Beitrags
über den Ausdruck $post->commentCount beziehen. Beim ersten Zugriff auf
diese Eigenschaft wird implizit eine SQL-Abfrage durchgeführt, um das
entsprechende Ergebnis zu bestimmen. Wie wir bereits wissen, handelt es sich
hierbei um den lazy loading-Ansatz. Wenn wir die Anzahl der Kommentare für
mehrere Beiträge bestimmen wollen, können wir auch die eager loading-Methode
verwenden:
$posts=Post::model()->with('commentCount', 'categoryCount')->findAll();Dieser Befehl führt drei SQL-Anweisungen aus um alle Beiträge zusammen mit der Anzahl
ihrer Kommentare und Kategorien zurückzuliefern. Würden wir den lazy
loading-Ansatz verwenden, würde das in 2*N+1 SQL-Abfragen resultieren, wenn
es N Beiträge gibt.
Standardmäßig wird eine statistische Abfrage unter Verwendung von COUNT
durchgeführt (was in obigem Beispiel für die Ermittlung der Anzahl der Kommentare und
Kategorien der Fall ist). Wir können dies über zusätzliche Optionen bei der
Deklaration in relations() anpassen. Hier die
verfügbaren Optionen:
select: Der statistische Ausdruck. Vorgabewert istCOUNT(*), was der Anzahl der Kindobjekte entspricht.defaultValue: Der Wert, der jenen Einträgen zugeordnet werden soll, für die die statistische Abfrage kein Ergenis liefert. Hat ein Beitrag z.B. keine Kommentare, würde seincommentCountdiesen Wert erhalten. Vorgabewert ist 0.condition: DieWHERE-Bedingung. Standardmäßig leer.params: Die Parameter, die an die erzeugte SQL-Anweisung gebunden werden sollen. Sie sollten als Array aus Namen-/Wert-Paare angegeben werden.order: DieORDER BY-Anweisung. Standardmäßig leer.group: DieGROUP BY-Anweisung. Standardmäßig leer.having: DieHAVING-Anweisung. Standarmäßig leer.
6. Relationale Abfragen mit benannten Bereichen ¶
Hinweis: Benannte Bereiche werden seit Version 1.0.5 unterstützt.
Auch relationale Abfragen können mit benannten Bereichen kombiniert werden. Dabei gibt es zwei Anwendungsfälle. Im ersten Fall werden benannte Bereiche auf das Hauptmodel, im zweiten auf die verbundenen Objekte angewendet.
Der folgende Code zeigt, wie benannte Bereiche mit dem Hauptmodel verwendet werden:
$posts=Post::model()->veroeffentlicht()->kuerzlich()->with('comments')->findAll();Dies unterscheidet sich kaum vom Vorgehen bei nicht-relationalen Abfragen. Der einzige
Unterschied besteht im zusätzlichen Aufruf von with() nach der Kette
benannter Bereiche. Diese Abfrage würde also die kürzlich veröffentlichten
Beiträge zusammen mit ihren Kommentaren zurückliefern.
Und der folgende Code zeigt die Anwendung benannter Bereiche auf verbundene Models:
$posts=Post::model()->with('comments:kuerzlich:freigegeben')->findAll();Diese Abfrage liefert alle Beiträge zusammen mit ihren freigegebenen
Kommentaren zurück. Beachten Sie, dass comments sich auf den Namen der
Beziehung bezieht, während kuerzlich und freigegeben zwei benannte
Bereiche sind, die in der Modelklasse Comment deklariert sind. Der
Beziehungsname und die benannten Bereiche sollten durch Doppelpunkte
getrennt werden.
Benannte Bereiche können auch in den in CActiveRecord::relations()
festgelegten with-Optionen einer Beziehung angegeben werden. Würden wir im
folgenden Beispiel auf $user->posts zugreifen, würden alle
freigegebenen Kommentare des Beitrags zurückgeliefert werden.
class User extends CActiveRecord
{
public function relations()
{
return array(
'posts'=>array(self::HAS_MANY, 'Post', 'authorID',
'with'=>'comments:freigegeben'),
);
}
}Hinweis: Bei relationalen Abfragen können nur benannte Bereiche verwendet werden, die in CActiveRecord::scopes definiert wurden. Daher können diese hier auch nicht parametrisiert werden.
Signup or Login in order to comment.